
As a pre-Christmas activity, while sane people are entering their final rush of the Christmas gifts chase, I spent some time with a study from the Universities of Guangzhou and Rutgers that looks at source coverage and citation bias in LLM-based search engines versus traditional search engines.
While some insights from the study come as obvious today, some of its conclusions surprised me.
The authors compare six LLM-based engines - Copilot, Gemini, ChatGPT, Perplexity, Grok, and Google AI Mode - against two traditional engines: Google and Bing. Their data collection was run in incognito mode, over a fixed period from July 16 to August 10. Here’s a short summary of it, and the insights I found interesting to share:
One of the first takeaways is straightforward: LLM-based search engines cite fewer sources and fewer domains than traditional search engines (what the paper calls « TSEs »). The gap is especially visible for Grok and Gemini: in the dataset, 82% of Grok answers and 38% of Gemini answers come with no sources at all, possibly because they rely more heavily on their training data.
More broadly, in 80% of LLM answers, there are fewer than 10 distinct URLs.
👉 This matters because when an interface synthesizes information into a single answer, the small number of citations increases the “winner-takes-most” dynamic: being included in those few references carries disproportionate weight. Within the SERP, you can show up in the 3rd, 10th, or even 20th position and still appear (even if it comes with very few clicks). This is not the case with LLMs: you appear… or you don’t.
We already know that LLMs don’t necessarily use the same sources as Google’s classic results. The study backs that up: LLM and traditional engines overlap on only about 38% of domains on average, and the differences can appear even within the same ecosystem (for example, Google AI Mode vs Gemini).
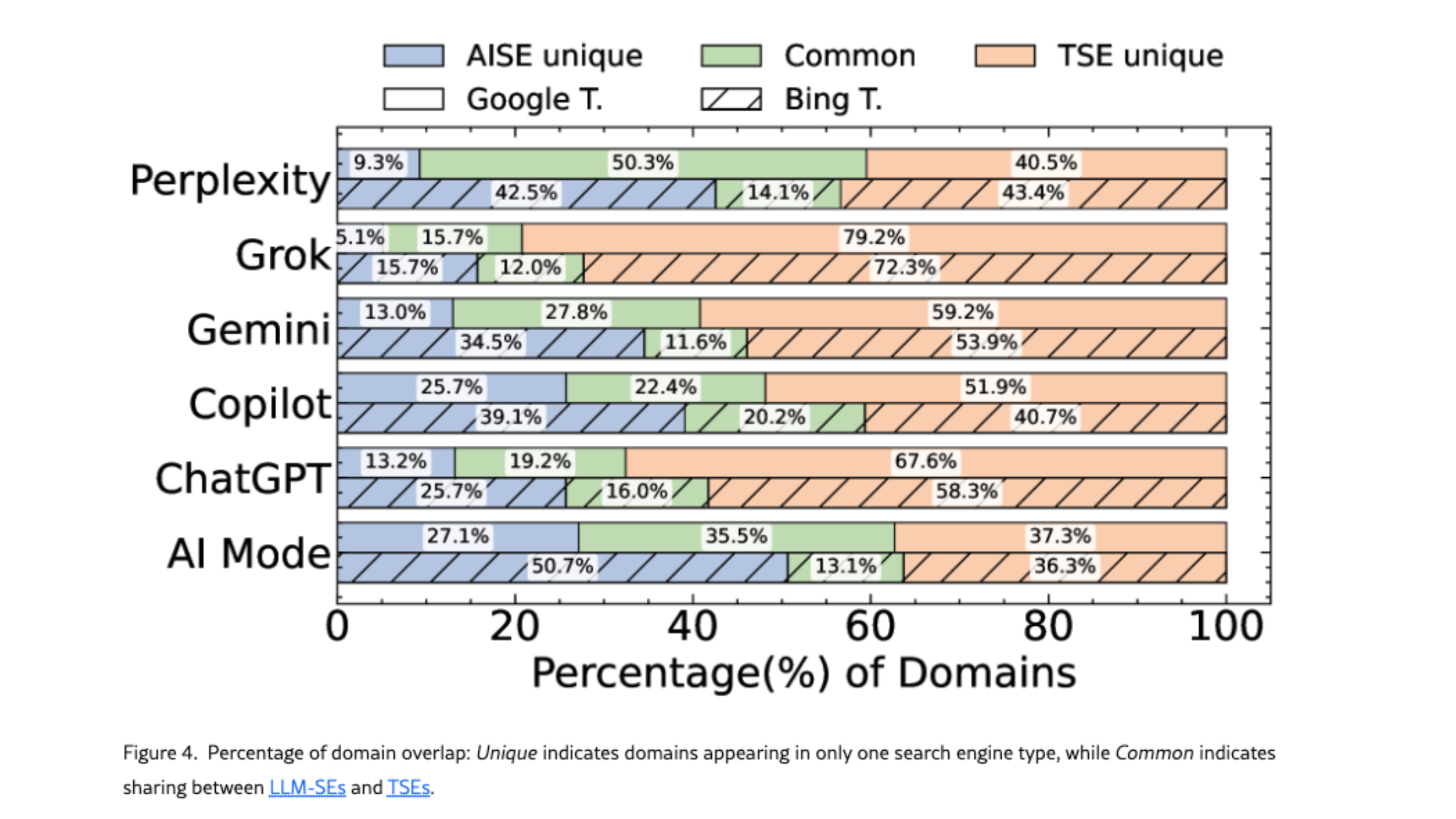
One thing that surprised me is that among the LLMs in the study, Perplexity is the one that shares the most domains with Google, while Grok and ChatGPT share the least. Google AI Mode stands out as comparatively balanced: roughly one third of its domains are unique, one third are shared with Google, and one third appear on Google only. Unsurprisingly, Copilot is the LLM that shares the most domains with Bing - they share 20,2% of common domains.
👉 This confirms that being cited in Gemini doesn’t mean you’ll appear in AI Mode (and vice versa), and that ranking well in Google or Bing doesn’t guarantee you’ll appear in a LLM.
Looking specifically at news-related citations, LLMs and traditional engines also diverge in what kinds of sources they favor. LLM-based engines tend to cite press agencies (for example Reuters and AP News) more often, while traditional search engines more frequently cite news websites (for example CNN and USA Today).
LLMs and TSEs cite different sources, but there’s an important nuance. For domains that are common to both systems, LLM engines tend to prioritize those that are ranked #1 in traditional search results. This means being top 3 in Google or Bing still has value - to some extent. Oof!
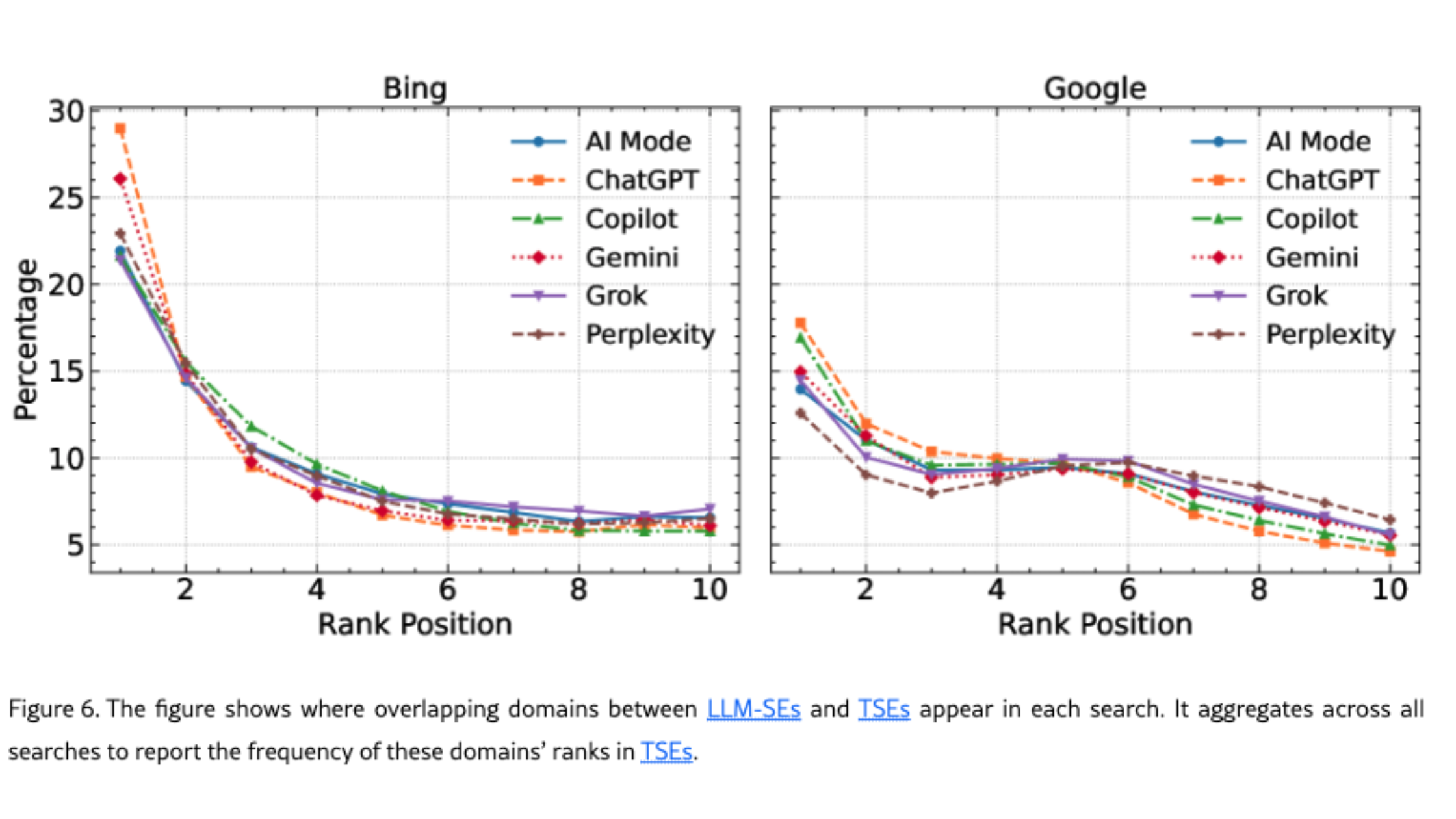
At the same time, across the board, LLM engines tend to send users toward less popular domains than traditional engines do. This is something we notice on our tool Semactic: some smaller domains show up in ChatGPT for prompts where we would expect bigger ones to appear.
👉 So the pattern isn’t “LLMs ignore traditional rankings” - it’s more like: they partly inherit the top of the stack, then roam elsewhere for the rest. The other key insight form this is that domain « weight » is not everything. Niche websites have their chance as well.
On credibility signals, one striking behavior is Gemini’s heavy reliance on Wikipedia for fact-checking, paired with relatively limited use of other sources. That’s not automatically “good” or “bad” - but it does mean the citation base can be narrow. The other LLMs seem more balanced in terms of reliable sources.
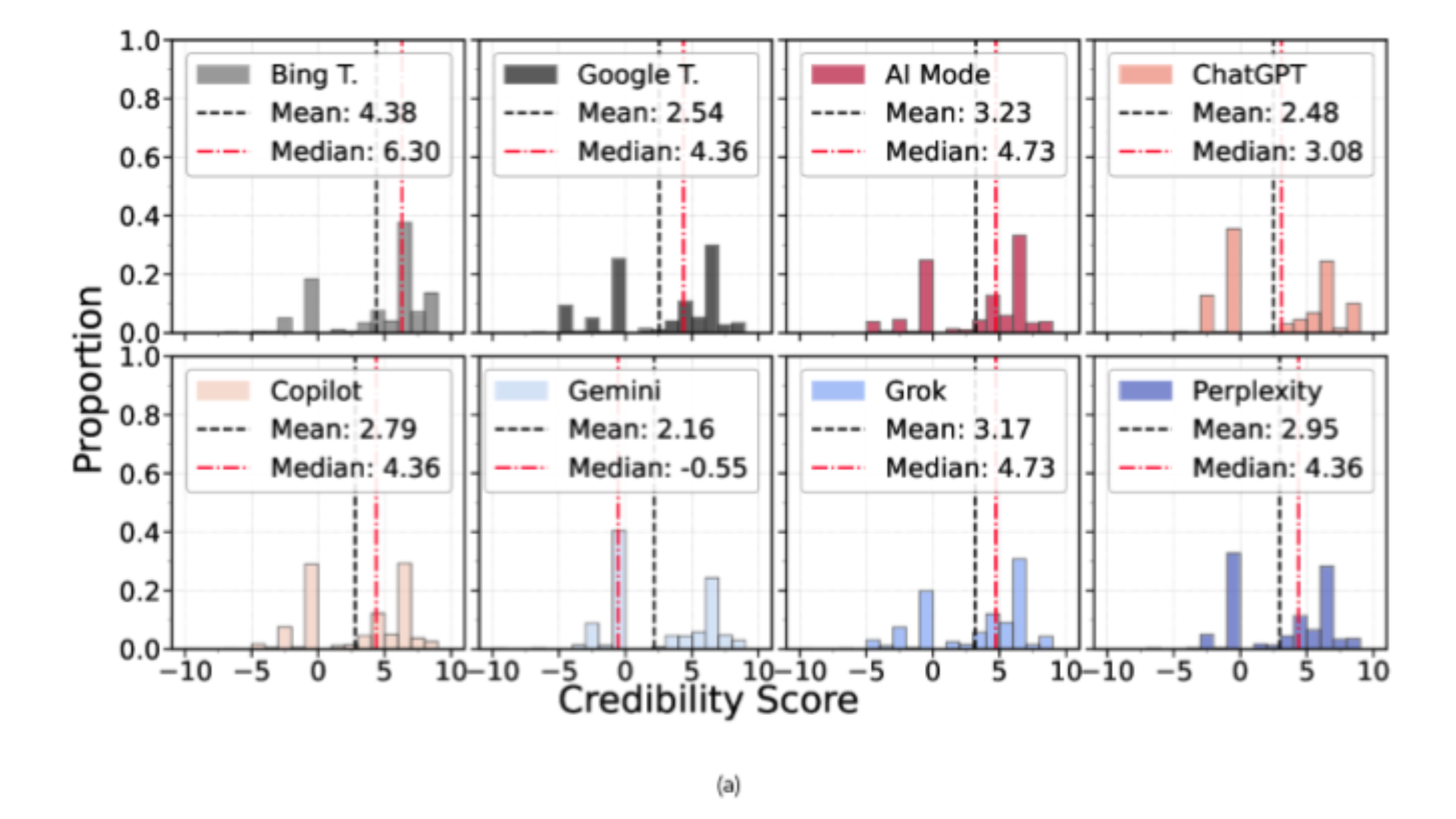
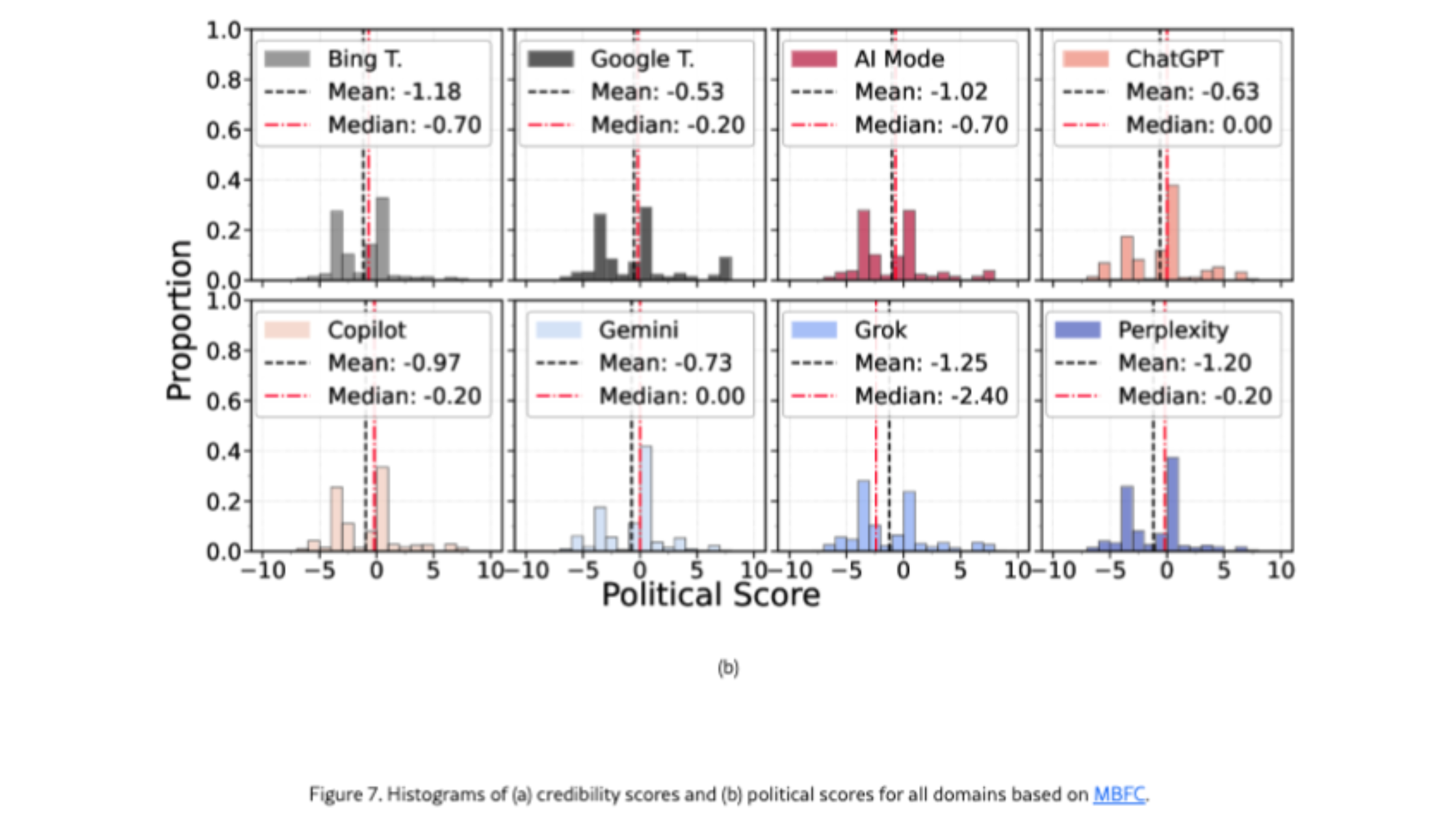
On political leaning, the study finds that the LLM engines in the sample display an overall left-leaning tendency. The more practical takeaway isn’t the direction itself, but the concentration: when a system cites very few domains, it can amplify exposure to a narrow ideological slice. Gemini is highlighted here because it cites fewer sources; Grok is highlighted for having the lowest neutrality score under the study’s domain-based metric. In short: Gemini and Grok rely on the fewest domains, but in different ways.
The cybersecurity section is especially important for brands. Microsoft and Google aren’t the best students in the class: the study observes that Copilot and Google contribute the largest share of total malicious domains returned, and that Gemini has a higher threat-per-answer rate.
The surprising part is the broader pattern: LLMs cite fewer sources overall, but not fewer malicious domains than traditional engines. Even more, the same malicious domains often appear for the same queries across both LLM and traditional search. And the queries that surface malicious domains tend to fall into four categories - Arts & Entertainment, People & Society, Finance, and Sports - which underlines an uncomfortable reality: “risky” queries are not necessarily niche or obviously sensitive.
👉 For SEO’s, this reinforces the necessity of tracking where your brand appears, which brands you’re associated with, and strengthening trust signals. Nothing really new.
The most actionable section looks at website characteristics that correlate with citation behavior. The study evaluates a set of HTML and readability signals, including:
Two patterns stand out:
The study also finds that LLM engines tend to favor domains with more outbound links.
👉 In the end, this backs up what we already suspected: webpage structure and readability are important factors for LLMs. The importance of outbound links, while it might appear surprising in the first glance, seems logical as well: they bring context to your website and your brand, and help LLMs better understand who you are.
Some insights of this study were surprising, others were nothing new. Here are the takeaways that feel the most interesting to me:




.svg)



