
Als pre-kerstactiviteit, terwijl normale mensen zich in hun laatste eindsprint voor kerstcadeaus storten, nam ik de tijd om een studie te lezen van de universiteiten van Guangzhou en Rutgers. Die studie analyseert de brondekking en citation bias van LLM-gebaseerde zoekmachines in vergelijking met traditionele zoekmachines.
Hoewel sommige inzichten uit de studie vandaag vrij evident zijn, hebben een aantal conclusies mij toch verrast.
De auteurs vergelijken zes LLM-gebaseerde zoekmachines — Copilot, Gemini, ChatGPT, Perplexity, Grok en Google AI Mode — met twee traditionele zoekmachines: Google en Bing. De dataverzameling gebeurde in incognitomodus, over een vaste periode van 16 juli tot 10 augustus. Hieronder volgt een korte samenvatting, en de inzichten die ik interessant vond om te delen:
Een van de eerste conclusies is vrij duidelijk: LLM-gebaseerde zoekmachines citeren minder bronnen en minder domeinen dan traditionele zoekmachines (die in de studie “TSE’s” worden genoemd). Het verschil is vooral zichtbaar bij Grok en Gemini: in de dataset bevat 82% van de Grok-antwoorden en 38% van de Gemini-antwoorden helemaal geen bronvermelding, mogelijk omdat ze sterker steunen op hun trainingsdata.
Meer algemeen geldt dat in 80% van de LLM-antwoorden minder dan 10 verschillende URL’s worden geciteerd.
👉 Dit is belangrijk, omdat wanneer een interface informatie samenbrengt in één enkel antwoord, het beperkte aantal citaties het “winner-takes-most”-effect versterkt: opgenomen worden in die paar referenties weegt onevenredig zwaar. In een klassieke SERP kan je op positie 3, 10 of zelfs 20 staan en toch zichtbaar zijn (zelfs al levert dat weinig clicks op). Bij LLM’s werkt dat anders: je verschijnt… of je verschijnt niet.
We weten al dat LLM’s niet noodzakelijk dezelfde bronnen gebruiken als de klassieke Google-resultaten. De studie bevestigt dit: LLM’s en traditionele zoekmachines overlappen gemiddeld slechts op ongeveer 38% van de domeinen, en die verschillen kunnen zelfs optreden binnen hetzelfde ecosysteem (bijvoorbeeld Google AI Mode vs Gemini).
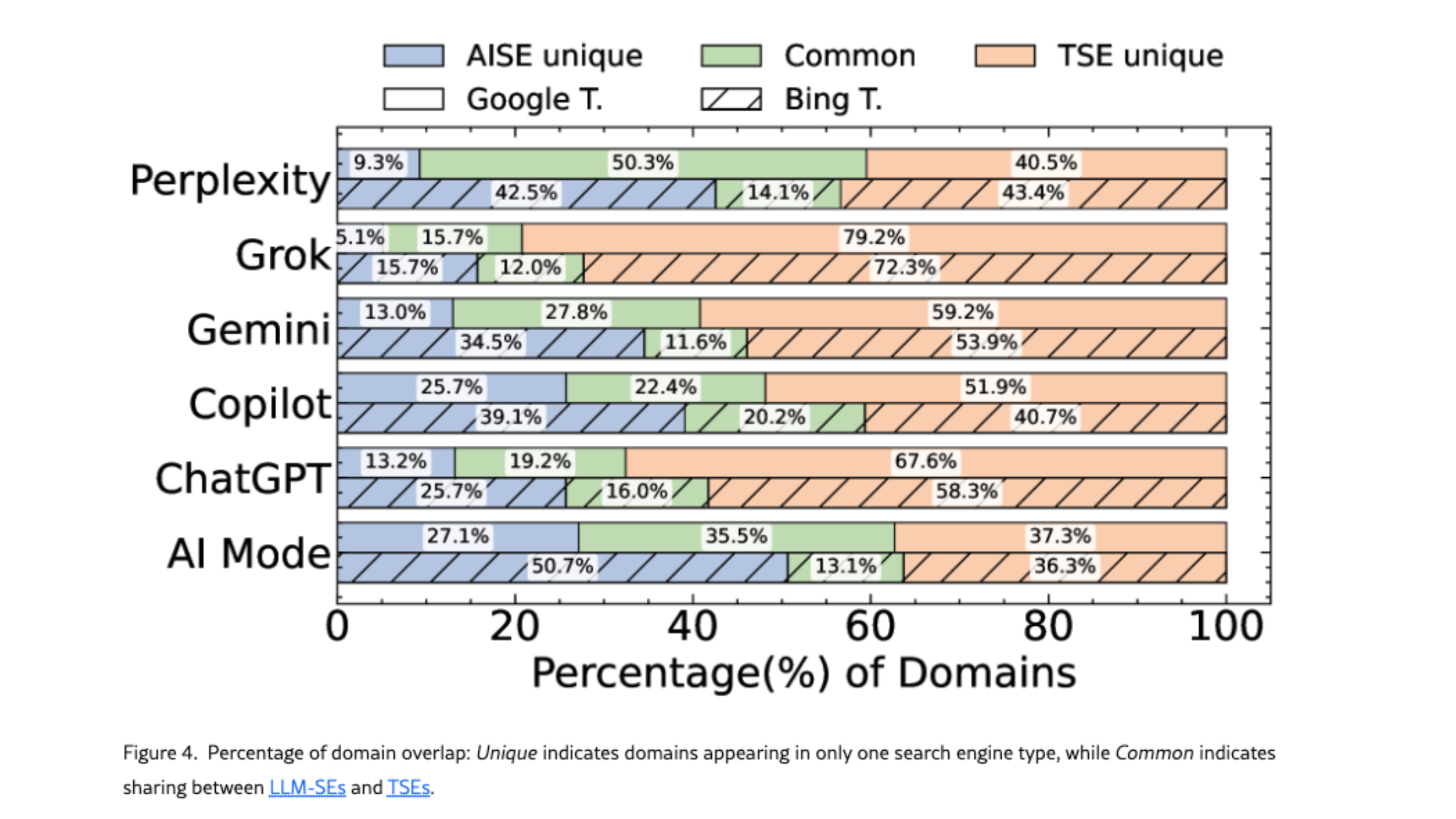
Wat mij verraste, is dat Perplexity binnen de LLM’s de meeste domeinen deelt met Google, terwijl Grok en ChatGPT het minst overlappen. Google AI Mode valt op als relatief evenwichtig: ongeveer een derde van de domeinen is uniek, een derde wordt gedeeld met Google en een derde verschijnt enkel in Google. Niet verrassend is Copilot de LLM die het meest overlapt met Bing - ze delen 20,2% van hun domeinen.
👉 Dit bevestigt dat geciteerd worden in Gemini niet betekent dat je ook verschijnt in AI Mode (en omgekeerd), en dat goed scoren in Google of Bing geen garantie is om zichtbaar te zijn in een LLM.
Wanneer we specifiek kijken naar nieuwsgerelateerde citaties, zien we dat LLM’s en traditionele zoekmachines ook verschillen in het type bronnen dat ze verkiezen. LLM’s citeren vaker persagentschappen (zoals Reuters en AP News), terwijl traditionele zoekmachines vaker nieuwswebsites citeren (zoals CNN en USA Today).
LLM’s en traditionele zoekmachines gebruiken verschillende bronnen, maar er is een belangrijke nuance. Voor domeinen die in beide systemen voorkomen, geven LLM’s meestal voorrang aan domeinen die op positie #1 staan in traditionele zoekresultaten. Dat betekent dat een top 3-positie in Google of Bing nog steeds waarde heeft - tot op zekere hoogte. Oef.
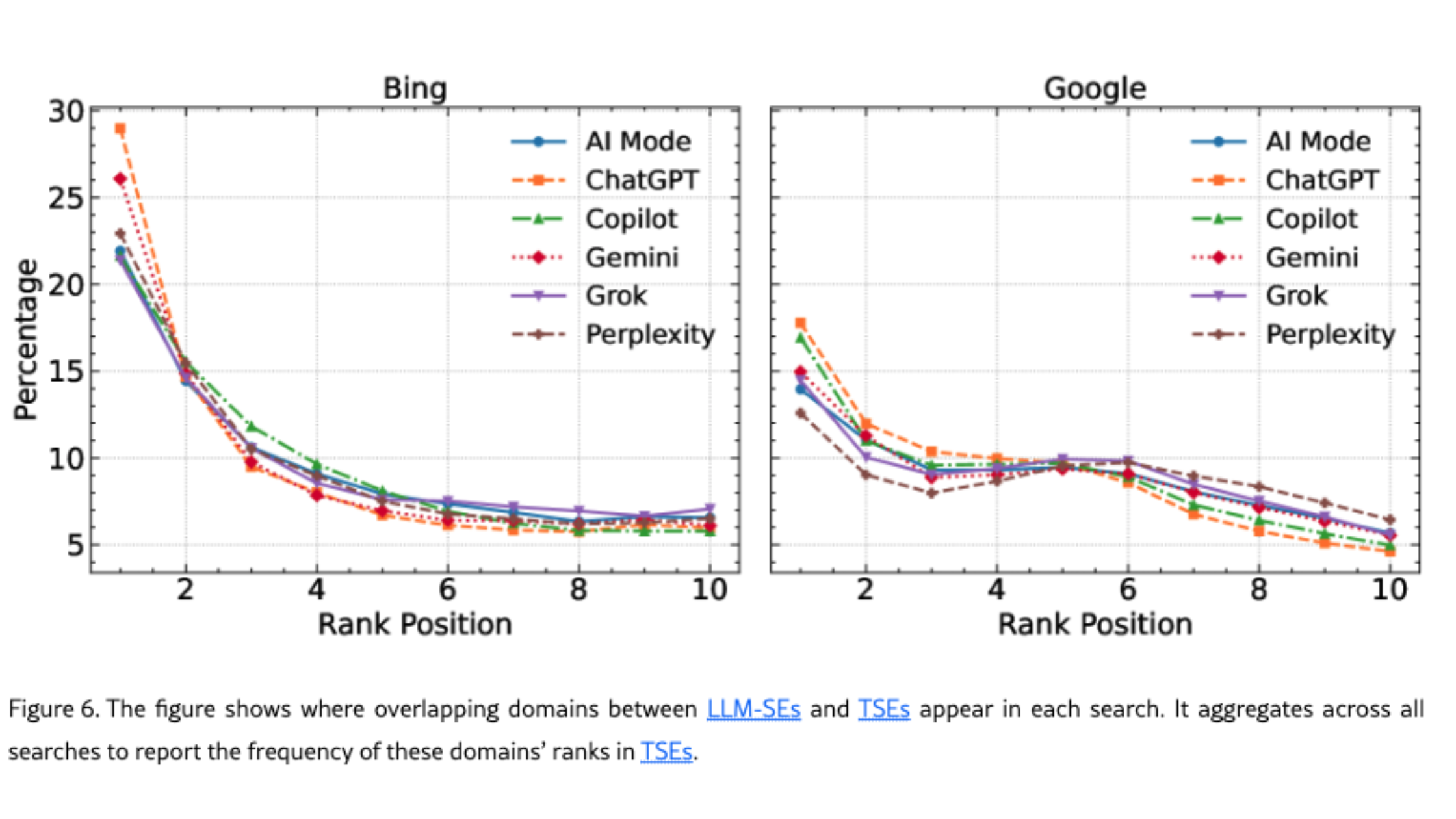
Tegelijkertijd sturen LLM’s gebruikers over het algemeen vaker door naar minder populaire domeinen dan traditionele zoekmachines. Dat zien we ook in onze tool Semactic: sommige kleinere domeinen verschijnen in ChatGPT bij prompts waar we grotere spelers zouden verwachten.
👉 Het patroon is dus niet “LLM’s negeren traditionele rankings”, maar eerder: ze nemen de top van de stapel gedeeltelijk over en verkennen daarbuiten andere bronnen. Een andere belangrijke conclusie is dat domein-‘gewicht’ niet alles is. Nichewebsites maken ook kans.
Wat geloofwaardigheid betreft, valt één gedrag bijzonder op: Gemini leunt sterk op Wikipedia voor factchecking, gecombineerd met een relatief beperkt gebruik van andere bronnen. Dat is op zich niet “goed” of “slecht”, maar het betekent wel dat de bronbasis erg smal kan zijn. De andere LLM’s lijken hierin meer gebalanceerd.
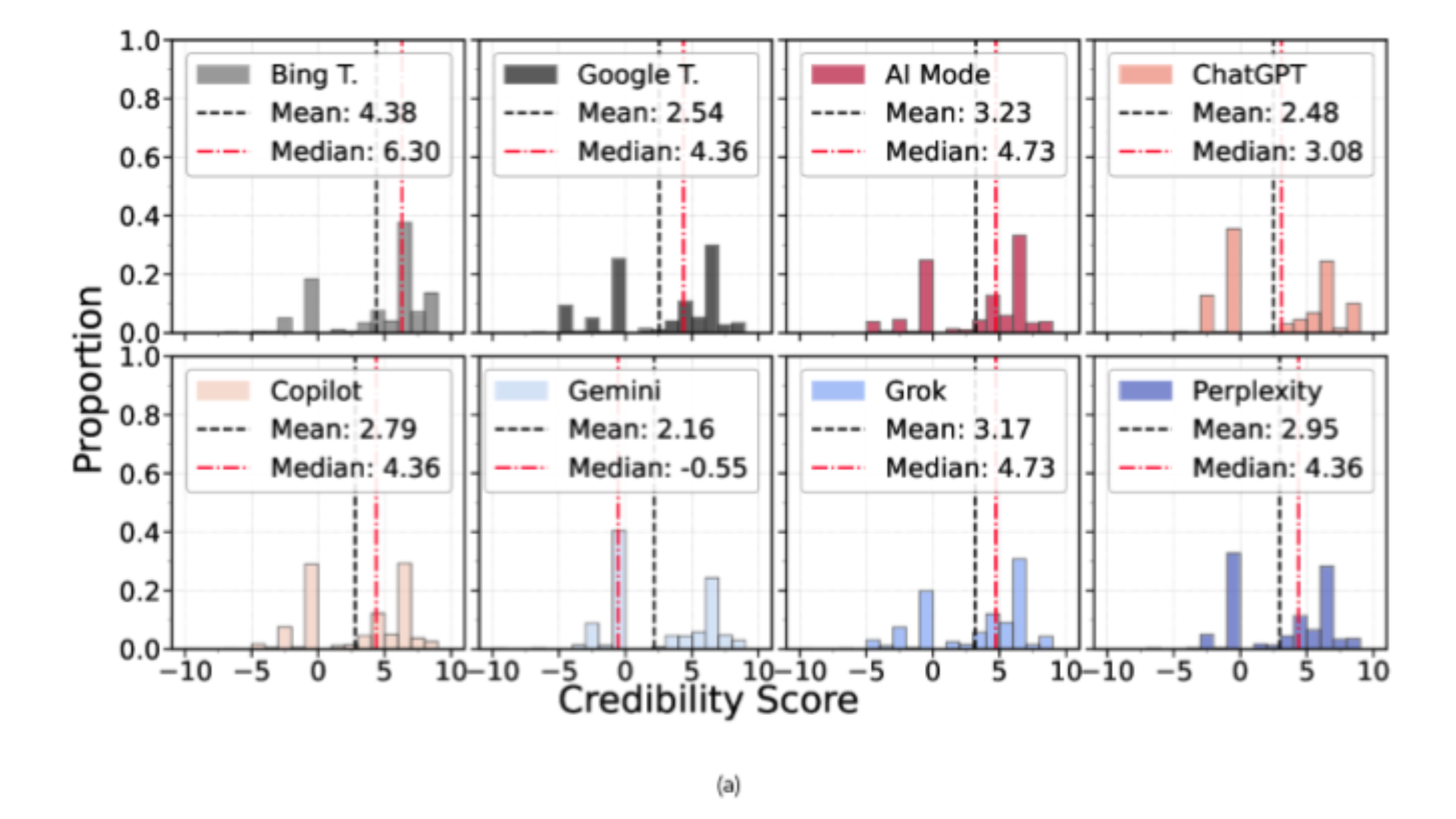
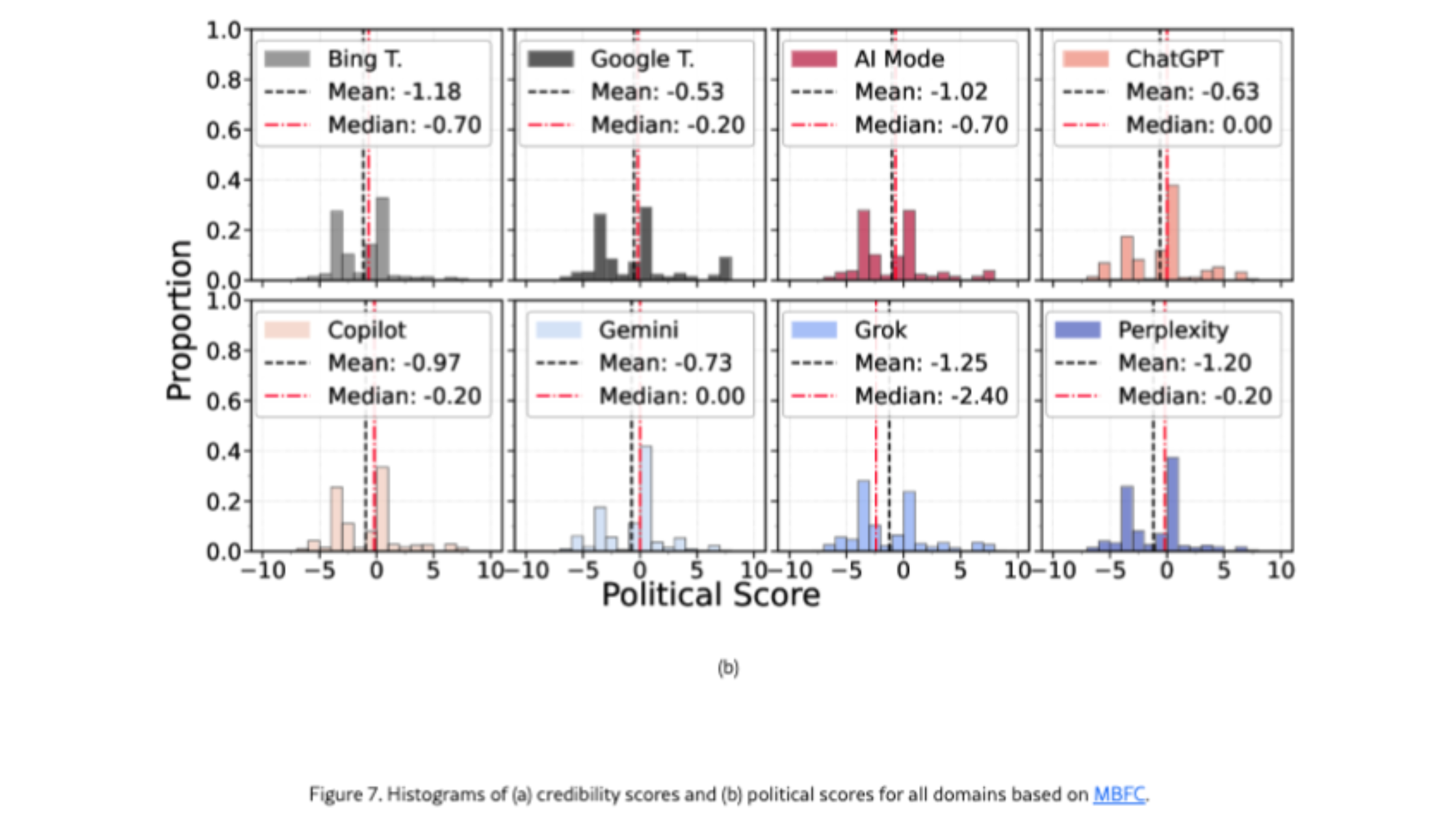
Wat politieke oriëntatie betreft, toont de studie aan dat de onderzochte LLM’s globaal een links georiënteerde tendens vertonen. De belangrijkste takeaway is echter niet de richting, maar de concentratie: wanneer een systeem zeer weinig domeinen citeert, kan het de blootstelling aan een beperkte ideologische invalshoek versterken. Gemini wordt hier genoemd omdat het weinig bronnen citeert; Grok omdat het de laagste neutraliteitsscore haalt volgens de domeingebaseerde metric van de studie. Kortom: Gemini en Grok steunen op de minste domeinen, maar op verschillende manieren.
Het cybersecurityluik is bijzonder relevant voor merken. Microsoft en Google blijken hier niet de beste leerlingen van de klas: de studie toont aan dat Copilot en Google het grootste aandeel kwaadaardige domeinen teruggeven, en dat Gemini een hogere dreiging per antwoord vertoont.
Wat verrassend is, is het bredere patroon: LLM’s citeren in totaal minder bronnen, maar niet minder kwaadaardige domeinen dan traditionele zoekmachines. Bovendien verschijnen dezelfde kwaadaardige domeinen vaak bij dezelfde zoekopdrachten, zowel in LLM’s als in traditionele zoekresultaten. De zoekopdrachten waarbij dit gebeurt, vallen vaak in vier categorieën - Arts & Entertainment, People & Society, Finance en Sports — wat een ongemakkelijke realiteit blootlegt: “risicovolle” queries zijn niet noodzakelijk niche of duidelijk gevoelig.
👉 Voor SEO-professionals onderstreept dit de noodzaak om te monitoren waar je merk verschijnt, met welke merken je wordt geassocieerd, en om vertrouwenssignalen te versterken. Niets echt nieuws, maar wel belangrijk.
Het meest actiegerichte deel van de studie focust op websitekenmerken die correleren met citatiegedrag. De auteurs analyseren een reeks HTML- en leesbaarheidssignalen, waaronder:
- Semantische tags: het gebruik van structurele elementen zoals <header>, <nav>, <main>, <article>, <section> en <footer>.
- Nesting depth: hoe diep de DOM-structuur gaat, als indicator voor structurele organisatie.
- Toegankelijkheidsfeatures: attributen zoals alt, role, aria-label en aria-hidden.
- Markup-fouten: het gebruik van verouderde tags zoals <font> en <center>.
- Flesch Reading Ease en Flesch–Kincaid Grade Level: leesbaarheidsmetingen gebaseerd op zinslengte en woordcomplexiteit.
Twee patronen springen eruit:
- Traditionele zoekresultaten neigen naar complexere content.
- LLM’s daarentegen geven de voorkeur aan meer leesbare en structureel duidelijke bronnen, wat wijst op een voorkeur voor content die zowel voor mensen als machines makkelijker te verwerken is.
Daarnaast blijkt dat LLM’s domeinen met meer outbound links vaker citeren.
👉 Dit bevestigt wat we al vermoedden: structuur en leesbaarheid van webpagina’s zijn belangrijke factoren voor LLM’s. Het belang van outbound links lijkt op het eerste gezicht verrassend, maar is logisch: ze bieden context over je website en je merk, en helpen LLM’s beter begrijpen wie je bent.
Sommige inzichten uit deze studie waren verrassend, andere minder. Dit zijn voor mij de meest relevante conclusies:




.svg)



