
À l’approche de Noël, pendant que les personnes raisonnables se lancent dans la dernière ligne droite de la chasse aux cadeaux, j’ai passé du temps sur une étude menée par les universités de Guangzhou et de Rutgers, qui analyse la couverture des sources et les biais de citation dans les moteurs de recherche basés sur les LLM, comparés aux moteurs de recherche traditionnels.
Si certains enseignements de l’étude paraissent aujourd’hui évidents, plusieurs de ses conclusions m’ont néanmoins surpris.
Les auteurs comparent six moteurs de recherche basés sur des LLM — Copilot, Gemini, ChatGPT, Perplexity, Grok et Google AI Mode — à deux moteurs traditionnels : Google et Bing. La collecte des données a été réalisée en mode navigation privée, sur une période fixe allant du 16 juillet au 10 août. Voici un résumé de l’étude et les points qui m’ont semblé les plus intéressants à partager.
L’un des premiers constats est assez direct : les moteurs de recherche basés sur des LLM citent moins de sources et moins de domaines que les moteurs de recherche traditionnels (appelés « TSEs » dans l’étude). L’écart est particulièrement marqué pour Grok et Gemini : dans le jeu de données, 82 % des réponses de Grok et 38 % de celles de Gemini ne comportent aucune source, possiblement parce qu’ils s’appuient davantage sur leurs données d’entraînement.
Plus largement, dans 80 % des réponses produites par des LLM, on trouve moins de 10 URLs distinctes.
👉 Cela est important, car lorsqu’une interface synthétise l’information en une réponse unique, le faible nombre de citations renforce une logique de type "winner-takes-most": être inclus dans ces quelques références confère un poids disproportionné. Dans une SERP classique, on peut apparaître en 3e, 10e, voire 20e position et rester visible (même avec peu de clics). Ce n’est pas le cas avec les LLM : soit vous apparaissez… soit vous n’existez pas.
On sait déjà que les LLM n’utilisent pas nécessairement les mêmes sources que les résultats classiques de Google. L’étude le confirme : les moteurs LLM et les moteurs traditionnels ne se recoupent qu’à environ 38 % des domaines en moyenne, et des différences peuvent apparaître même au sein d’un même écosystème (par exemple entre Google AI Mode et Gemini).
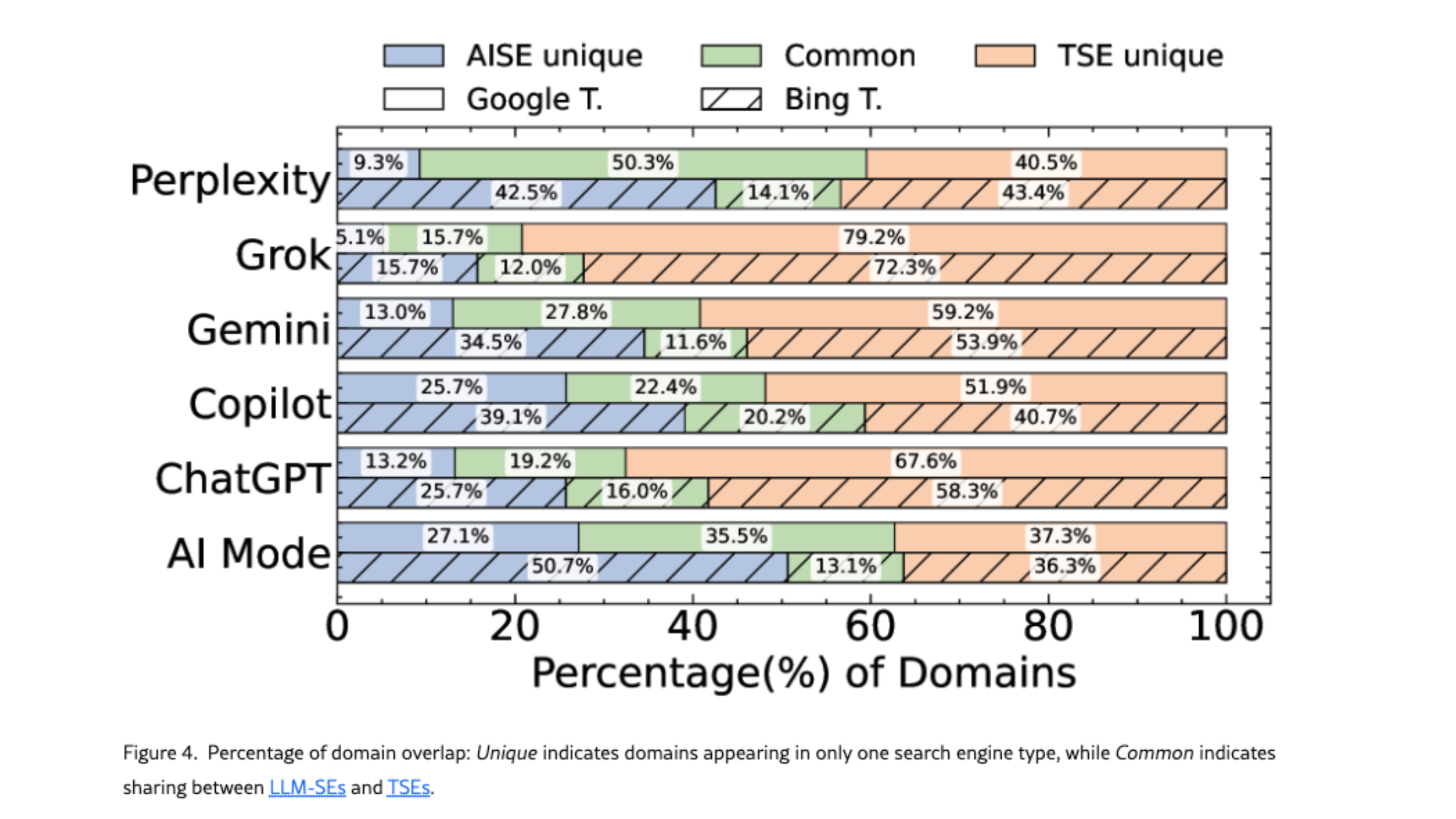
Un point qui m’a surpris: parmi les LLM analysés, Perplexity est celui qui partage le plus de domaines avec Google, tandis que Grok et ChatGPT en partagent le moins. Google AI Mode se distingue par un équilibre relatif : environ un tiers de ses domaines sont uniques, un tiers sont partagés avec Google, et un tiers apparaissent uniquement sur Google. Sans surprise, Copilot est le LLM qui partage le plus de domaines avec Bing - avec 20,2 % de domaines communs.
👉 Cela confirme qu’être cité dans Gemini ne signifie pas nécessairement apparaître dans AI Mode (et inversement), et qu’un bon classement sur Google ou Bing ne garantit pas une visibilité dans un LLM.
En se concentrant spécifiquement sur les citations liées à l’actualité, les LLM et les moteurs traditionnels divergent également sur les types de sources privilégiées. Les moteurs basés sur des LLM ont tendance à citer plus souvent des agences de presse (comme Reuters ou AP News), tandis que les moteurs de recherche traditionnels citent plus fréquemment des sites d’actualité (comme CNN ou USA Today).
Les LLM et les moteurs traditionnels citent des sources différentes, mais une nuance importante mérite d’être soulignée. Pour les domaines communs aux deux systèmes, les moteurs LLM ont tendance à privilégier ceux qui sont classés en première position dans les résultats de recherche traditionnels. Cela signifie qu’être dans le top 3 de Google ou Bing conserve une certaine valeur - dans une certaine mesure. Ouf!
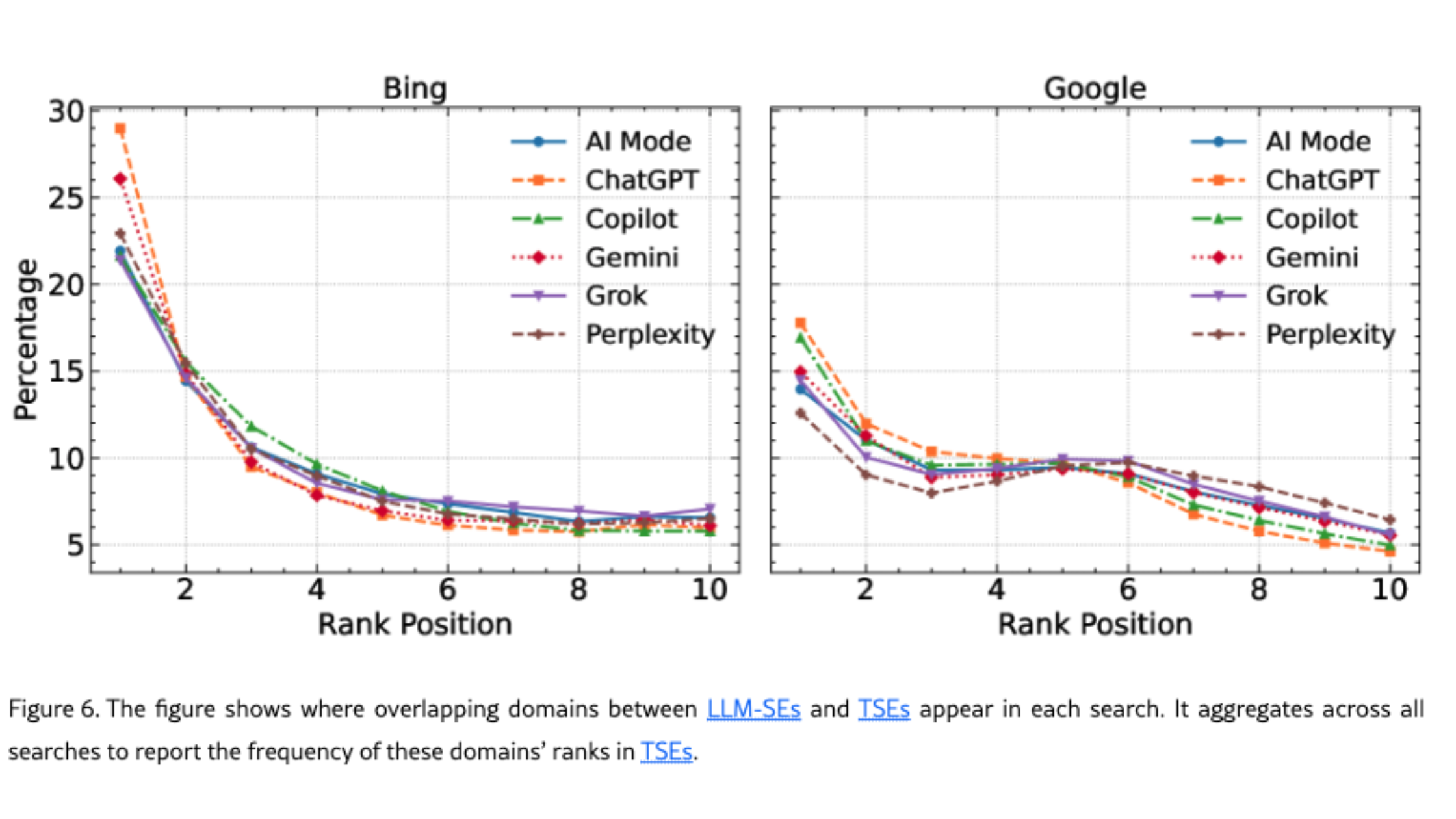
Dans le même temps, de manière générale, les moteurs LLM orientent davantage les utilisateurs vers des domaines moins populaires que ne le font les moteurs traditionnels. C’est quelque chose que nous observons dans notre outil Semactic : certains petits domaines apparaissent dans ChatGPT pour des requêtes où l’on s’attendrait plutôt à voir des acteurs majeurs.
👉 Le schéma n’est donc pas "les LLM ignorent les classements traditionnels", mais plutôt qu’ils héritent partiellement du sommet de la pile, puis explorent ailleurs pour le reste. Un autre enseignement clé est que le "poids" d’un domaine n’est pas tout : les sites de niche ont eux aussi leur chance.
En matière de signaux de crédibilité, un comportement marquant est la forte dépendance de Gemini à Wikipédia pour la vérification des faits, combinée à un usage relativement limité d’autres sources. Ce n’est ni intrinsèquement "bon » ni « mauvais", mais cela signifie que la base de citations peut être étroite. Les autres LLM semblent plus équilibrés en termes de diversité de sources fiables.
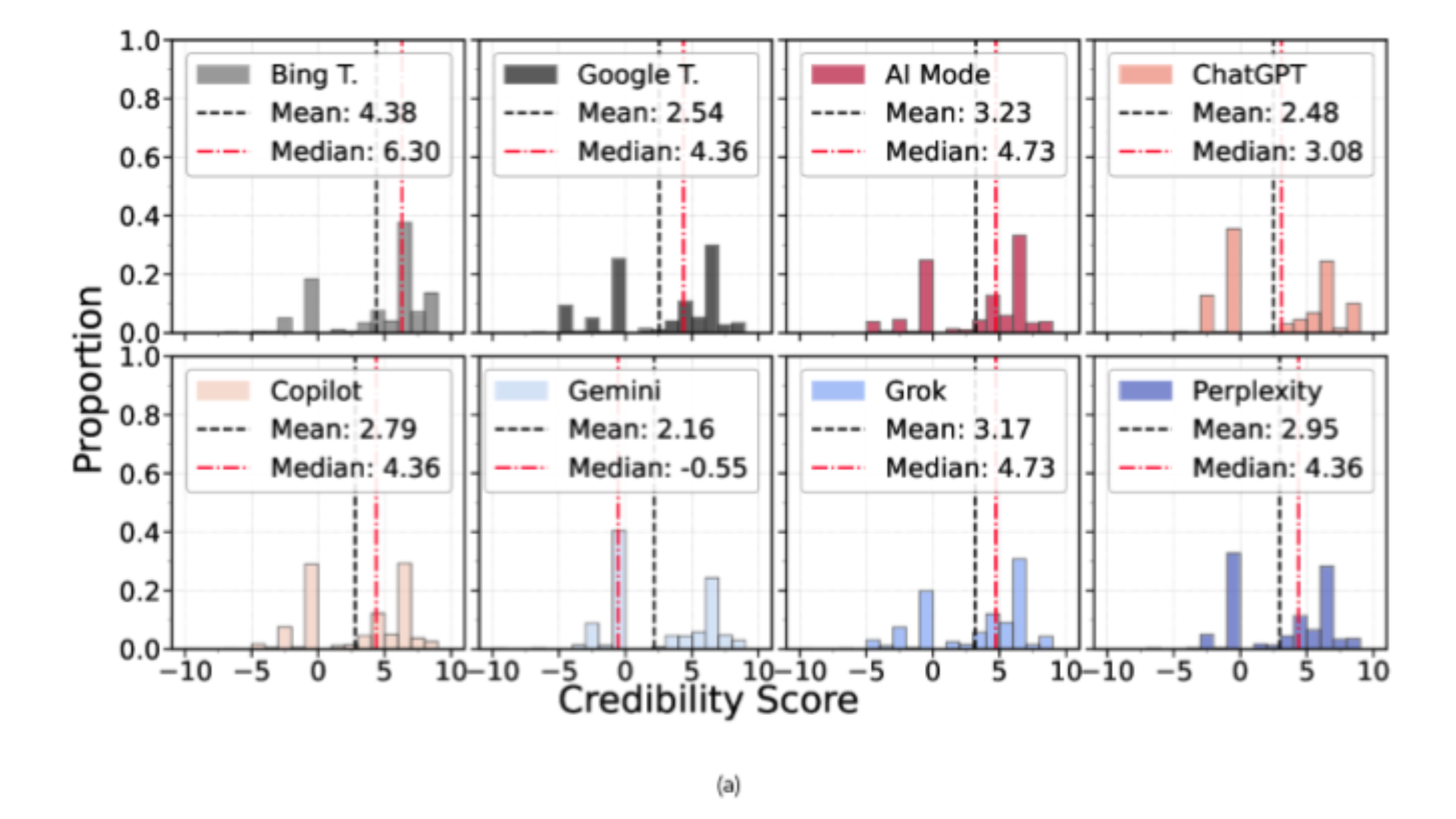
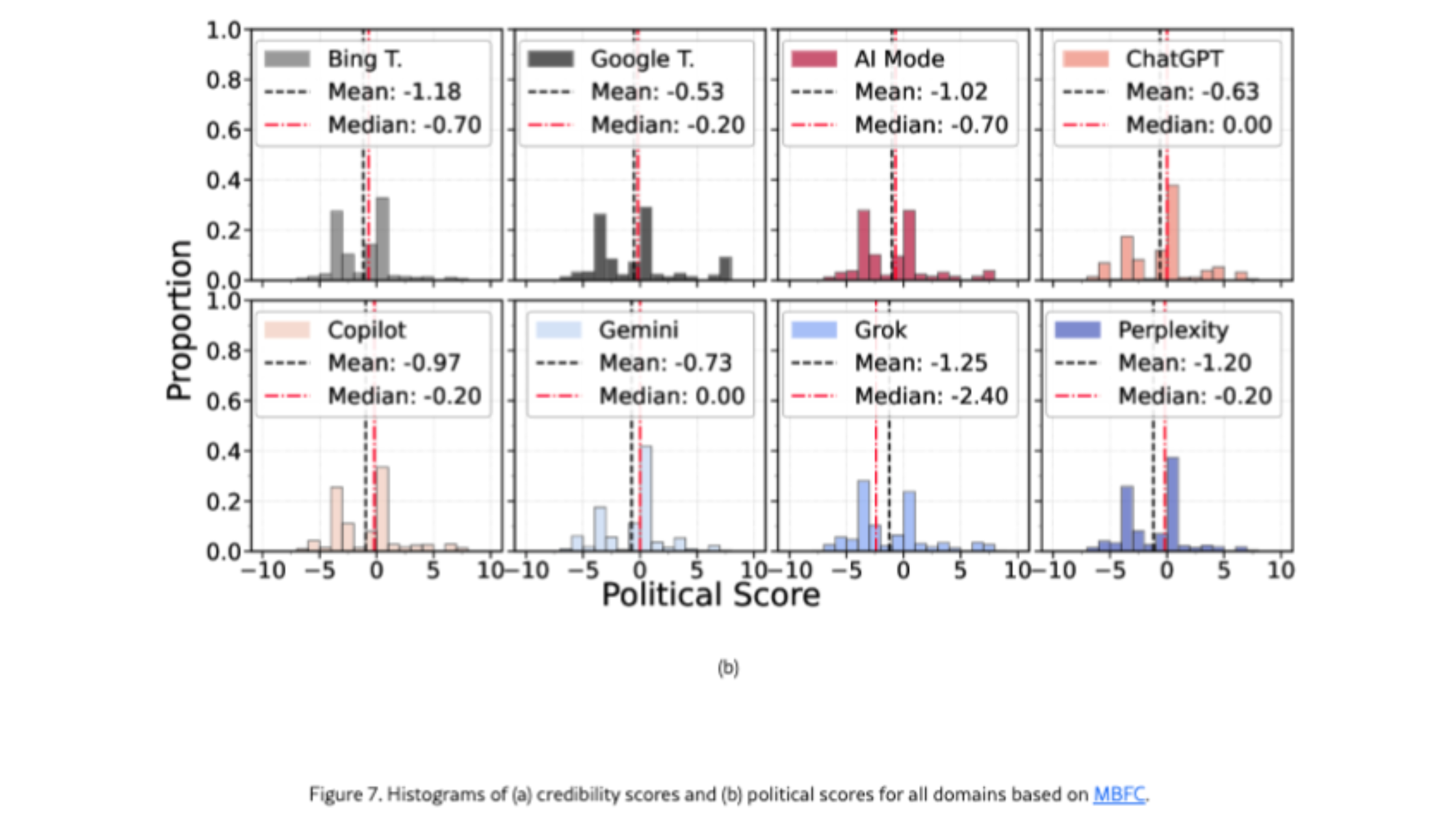
Concernant l’orientation politique, l’étude constate que les moteurs LLM de l’échantillon présentent une tendance globalement orientée à gauche. L’enjeu principal n’est toutefois pas tant la direction que la concentration: lorsqu’un système cite très peu de domaines, il peut amplifier l’exposition à un spectre idéologique restreint. Gemini est mis en avant ici parce qu’il cite peu de sources; Grok est souligné pour avoir le score de neutralité le plus faible selon la métrique utilisée dans l’étude. En résumé : Gemini et Grok s’appuient sur très peu de domaines, mais de manière différente.
La partie consacrée à la cybersécurité est particulièrement importante pour les marques. Microsoft et Google ne sont pas les meilleurs élèves: l’étude observe que Copilot et Google contribuent à la plus grande part des domaines malveillants retournés, et que Gemini présente un taux de menace par réponse plus élevé.
L’aspect surprenant réside dans le schéma global: les LLM citent moins de sources au total, mais pas moins de domaines malveillants que les moteurs traditionnels. Pire encore, les mêmes domaines malveillants apparaissent souvent pour les mêmes requêtes, à la fois dans les LLM et dans la recherche classique. Les requêtes qui font remonter ces domaines appartiennent majoritairement à quatre catégories - Arts & Divertissement, Personnes & Société, Finance et Sports - ce qui souligne une réalité inconfortable : les requêtes « à risque » ne sont pas nécessairement de niche ou manifestement sensibles.
👉 Pour les SEO, cela renforce la nécessité de surveiller où votre marque apparaît, avec quelles autres marques elle est associée, et de renforcer les signaux de confiance. Rien de vraiment nouveau.
La section la plus actionnable s’intéresse aux caractéristiques des sites web corrélées aux comportements de citation. L’étude évalue un ensemble de signaux HTML et de lisibilité, notamment:
<header>, <nav>, <main>, <article>, <section> et <footer>.alt, role, aria-label et aria-hidden.<font> et <center>.Deux tendances se dégagent:
L’étude montre également que les moteurs LLM favorisent les domaines comportant davantage de liens sortants.
👉 En fin de compte, cela confirme ce que nous soupçonnions déjà: la structure des pages et la lisibilité sont des facteurs importants pour les LLM. L’importance des liens sortants, bien que surprenante au premier abord, semble également logique: ils apportent du contexte à votre site et à votre marque, et aident les LLM à mieux comprendre qui vous êtes.
Certaines conclusions de cette étude m’ont surpris, d’autres étaient déjà bien connues. Voici les enseignements qui me semblent les plus intéressants:




.svg)



