
At Google I/O 2026, Google adopted a formulation that looks less like a slogan than a repositioning of the product: “Google Search is AI Search”.
Search is becoming natively conversational and multimodal, capable of absorbing long, contextual queries mixing text, images and other content, and answers are increasingly organised into continuous threads rather than simple lists of links. On top of this, Google highlights agents capable of monitoring topics over time and notifying the user, without them having to repeatedly run the same queries in loops.
In e-commerce, we see the same logic with work around “agentic commerce” and protocols such as UCP, which aim to allow agents to explore catalogues, compare offers and fill carts on behalf of the user. The challenge is no longer only to appear in a results page, but to be understandable and actionable in these agent-driven journeys.
In other words: the question is no longer “are my pages visible?”, but also “can my website be effectively used by AI agents?”
In this broader landscape, one point particularly caught my attention: the arrival of WebMCP on the browser side. Chrome presents it as a proposed web standard to allow pages to declare structured tools that agents can use, rather than letting them guess by scraping the DOM.
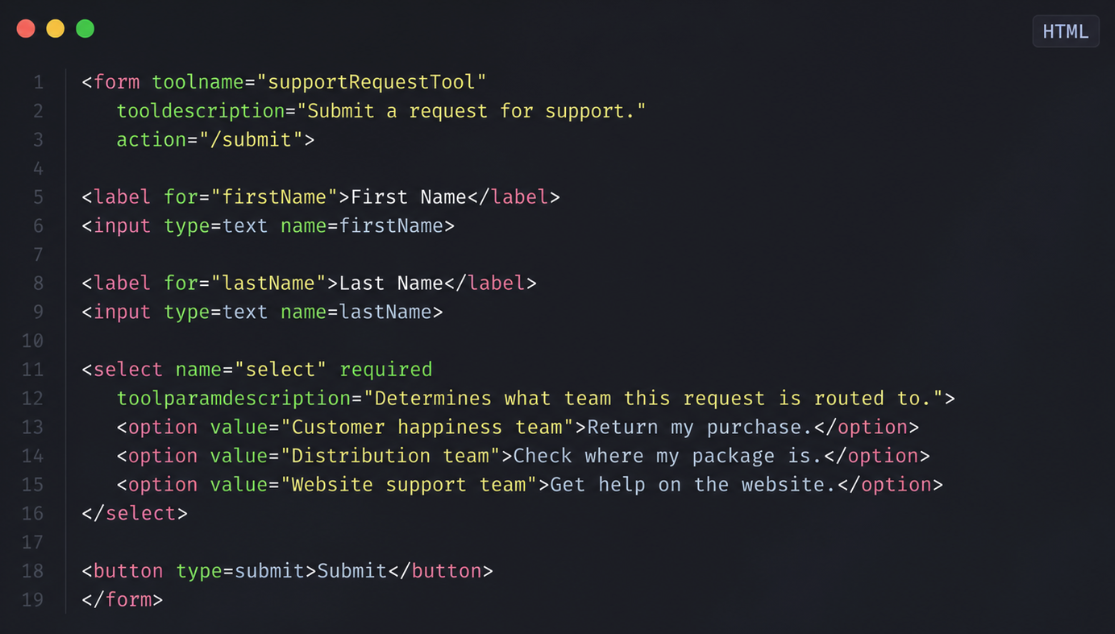
In a recent post, Bastian Grimm relays the WebMCP announcement and focuses on one particular point: the announcement and the specification explain that HTML forms can be exposed as tools usable by agents, provided they are annotated with a few dedicated attributes. WebMCP does not try to turn the web into a giant API, but to make explicit, for agents, what the page allows to do: which actions are possible, what the fields are for, how to trigger the action.
The WebMCP specification describes two ways of exposing these actions:
In the declarative case, a simple <form> can become a tool usable by an agent by adding a few attributes such as toolname (name of the action), tooldescription (what the form allows to do) or toolparamdescription (what each field represents). The browser then translates this form into a structured representation that an agent can use, in the same way as an MCP tool on the server side.
In other words: the same search, contact or booking form that your users fill in today can, with very few changes, become a clearly readable and reusable capability for an agent, instead of just a UI block it has to interpret.
What WebMCP highlights is a gap that has existed for a long time: in HTML, we indicate where to send data (action) and how (method), but we almost never explicitly say what the form allows to do or what each field really represents.
These new attributes fill exactly this gap: they force to name the action and document the parameters, which is useful for agents… and very concretely for accessibility, maintenance and human readability.
From an SEO/GEO perspective, the point is not to rush into a full implementation of WebMCP.
The question is: if an agent had to help a user complete a task on my website, what could it actually understand and execute?
On forms, this becomes very concrete:
If you had to write a proper toolname and tooldescription for your key forms tomorrow, would it be trivial, or would you end up redesigning the whole journey for it to make sense?
WebMCP does not solve all of this, but it provides a useful lens: thinking of a website not only as a set of pages, but as a set of well-defined actions that can eventually be exposed to agents.
A recurring reaction around WebMCP is: “perfect for scammers and spammers, they will be the first to use it”.
It is not an unreasonable concern. Every new automation capability creates new vectors for spam, fake leads and mass form submissions.
Chrome documentation and WebMCP discussions make it clear that the standard defines how tools are declared, but does not handle security on the model or agent side. That responsibility remains with websites.
Server-side validation, rate limiting, anomaly detection and defining what should or should not be exposed remain essential.
Without going into detail, at least three common-sense rules emerge:
WebMCP does not create the spam problem; it mainly reminds us that making a site usable by agents also requires solid backend hygiene.
Today, WebMCP is still in preview mode in Chrome, available as an experimental feature for developers.
It is not a production standard, nor a requirement for SEO.
The ecosystem around it (tools, best practices, security, visibility strategies) is still emerging.
In a related discussion around llms.txt, John Mueller recently summarised the situation with a phrase that applies very well here: “prioritize needs before dreams”.
The discussion was about another file and another signal, but the principle applies here as well.
Following WebMCP and the broader agentic web, yes. Understanding what these building blocks say about where the web is going, yes. But without losing sight of the fundamentals:
That is what will make the difference for humans, and by extension for the agents assisting them.
Structure, explicit intent, well-defined actions. The foundations remain the same. It is the surface - and the agents moving across it - that is changing.




.svg)



