
À Google I/O 2026, Google a assumé une formule qui ressemble moins à un slogan qu’à un repositionnement du produit : « Google Search is AI Search ».
La recherche devient nativement conversationnelle et multimodale, capable d’absorber des requêtes longues et contextuelles mêlant texte, images et autres contenus, et les réponses s’organisent de plus en plus en fils continus plutôt qu’en simples listes de liens. Par‑dessus, Google met en avant des agents capables de surveiller des sujets dans le temps et de notifier l’utilisateur, sans qu’il doive relancer les mêmes requêtes en boucle.
Dans l’e-commerce, on voit la même logique avec les travaux autour de l’agentic commerce” et de protocoles comme l’UCP, qui visent à permettre à des agents d’explorer des catalogues, comparer des offres et remplir des paniers au nom de l’utilisateur. L’enjeu n’est plus seulement d’apparaître dans une page de résultats, mais d’être compréhensible et actionnable dans ces parcours pilotés par des agents.
Autrement dit : la question ne s’arrête plus à “est‑ce que mes pages sont visibles ?”, elle devient aussi “est‑ce que mon site peut être utilisé efficacement par des agents IA ?”.
Dans ce paysage plus large, un point m’a particulièrement retenu : l’arrivée de WebMCP côté navigateur. Chrome le présente comme une proposition de standard Web pour permettre aux pages de déclarer des outils structurés que des agents peuvent utiliser, plutôt que de les laisser deviner en scrappant le DOM.
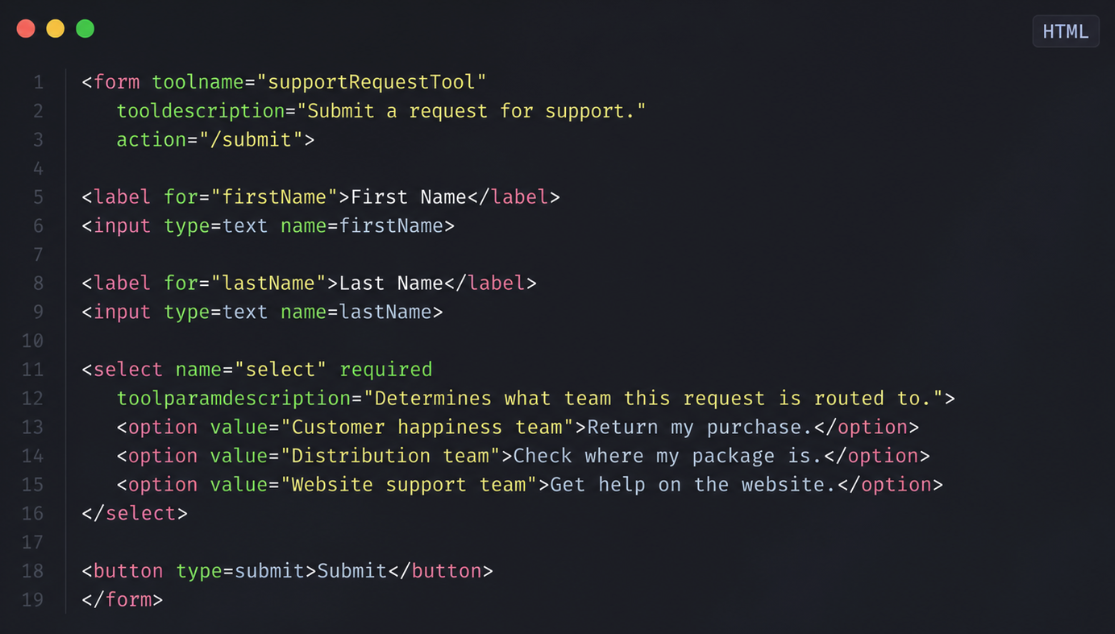
Dans un post récent, Bastian Grimm relaie l’annonce de WebMCP et s’attarde sur un point en particulier : l’annonce et la spécification expliquent que les formulaires HTML peuvent être exposés comme des outils exploitables par des agents, à condition d’être annotés avec quelques attributs dédiés. WebMCP ne cherche pas à transformer le web en une API géante, mais à rendre explicite, pour les agents, ce que la page permet de faire : quelles actions sont possibles, à quoi servent les champs, comment déclencher l’action.
La spécification WebMCP décrit deux façons d’exposer ces actions :
Dans le cas déclaratif, une simple balise <form> peut devenir un outil exploitable par un agent en ajoutant quelques attributs comme toolname (nom de l’action), tooldescription (ce que permet de faire le formulaire) ou toolparamdescription (ce que représente chaque champ). Le navigateur traduit ensuite ce formulaire en représentation structurée qu’un agent peut utiliser, au même titre qu’un outil MCP côté serveur.
En d’autres termes : le même formulaire de recherche, de contact ou de réservation que vos utilisateurs remplissent aujourd’hui peut, avec très peu de changements, devenir une capacité clairement lisible et réutilisable par un agent, au lieu d’être un simple bloc d’UI qu’il doit interpréter.
Ce que WebMCP met en lumière, c’est un manque que l’on traîne depuis longtemps : en HTML, on indique où envoyer les données (action) et comment (method), mais on ne dit presque jamais explicitement ce que le formulaire permet de faire ni ce que chaque champ représente vraiment.
Les nouveaux attributs comblent exactement ce trou : ils forcent à nommer l’action et à documenter les paramètres, ce qui est utile pour les agents… et, très concrètement, pour l’accessibilité, la maintenance et la lisibilité côté humain.
Vu depuis le SEO/GEO, l’enjeu n’est pas de se précipiter vers une implémentation exhaustive de WebMCP. L’enjeu, c’est de regarder son site avec une question en tête : si un agent devait aider un humain à accomplir une tâche chez moi, qu’est‑ce qu’il pourrait réellement comprendre et exécuter ?
Sur les formulaires, cela devient très concret :
Si tu devais, demain, écrire un toolname et un tooldescription propres pour tes formulaires clés, est‑ce que ce serait trivial, ou est‑ce que tu te retrouverais à réécrire tout le parcours pour que ça ait du sens ?
WebMCP ne résout pas tout ça, mais il donne une grille de lecture utile : penser son site non seulement comme un ensemble de contenus, mais comme un ensemble d’actions bien définies que l’on pourra, à terme, exposer aux agents.
Une réaction récurrente autour de WebMCP est : “parfait pour les scammers et les spammers, ils seront les premiers à s’en servir”. Elle est loin d’être idiote. Chaque nouvelle possibilité d’automatisation crée un nouveau vecteur potentiel pour le spam, les faux leads, les soumissions massives de formulaires.
Les documents de Chrome et les discussions autour de WebMCP rappellent d’ailleurs que le standard définit comment déclarer des outils, mais qu’il ne gère pas tout ce qui relève de la sécurité côté modèles ou côté agents. Les contrôles restent du ressort des sites : validation serveur, limites de fréquence, détection de patterns anormaux, définition de ce qu’on expose ou pas.
Sans rentrer dans les détails, cela suggère au moins trois règles de bon sens :
WebMCP, en soi, ne crée pas le problème du spam ; il rappelle surtout que rendre un site exploitable par des agents suppose d’avoir aussi une vraie hygiène côté back.
Aujourd’hui, WebMCP est encore en mode preview dans Chrome, activable pour les développeurs dans des versions de test. Ce n’est pas un prérequis, ni un standard déployé en production sur l’ensemble du web. L’écosystème autour (outils, bonnes pratiques, sécurité, intégration dans les stratégies de visibilité) est encore en train de se construire.
Dans un contexte voisin, autour de llms.txt, John Mueller rappelait récemment (dans un échange relayé par Lily Ray) une phrase qui résume assez bien la situation : “prioritize needs before dreams”. La discussion portait sur un autre fichier et un autre signal, mais le principe général s’applique très bien ici.
Suivre WebMCP et plus largement le web agentique, oui. Comprendre ce que ces briques disent de la direction que prend le web, oui. Mais sans sacrifier les fondamentaux :
C’est cela qui fera la différence pour les humains et, par ricochet, pour les agents qui les assistent.
Structure claire, intentions explicites, actions bien définies. Les fondations restent les mêmes. C’est la surface, et les agents qui s’y déplacent, qui est en train de changer.




.svg)



