
Tijdens Google I/O 2026 nam Google een formulering aan die minder aanvoelt als een slogan dan als een productherpositionering: “Google Search is AI Search.”
Search wordt van nature conversationeel en multimodaal, in staat om lange, contextuele zoekopdrachten te verwerken die tekst, beelden en andere content combineren, en antwoorden worden steeds vaker georganiseerd in doorlopende threads in plaats van eenvoudige lijsten met links. Daarbovenop zet Google in op agents die onderwerpen in de tijd kunnen opvolgen en de gebruiker kunnen notificeren, zonder dat die telkens opnieuw dezelfde zoekopdrachten hoeft uit te voeren.
In e-commerce zien we dezelfde logica met ontwikkelingen rond agentic commerce en protocollen zoals UCP, die erop gericht zijn om agents catalogi te laten verkennen, aanbiedingen te vergelijken en winkelmandjes te vullen namens de gebruiker. De uitdaging is niet langer alleen zichtbaar zijn in een resultatenpagina, maar ook begrijpbaar en uitvoerbaar zijn binnen deze door agents gestuurde journeys.
Met andere woorden: de vraag is niet langer alleen “zijn mijn pagina’s zichtbaar?”, maar ook “kan mijn website effectief gebruikt worden door AI-agents?”
In dit bredere landschap viel één punt mij bijzonder op: de komst van WebMCP aan de browserzijde. Chrome presenteert dit als een voorstel voor een webstandaard die pagina’s in staat stelt om gestructureerde tools te declareren die agents kunnen gebruiken, in plaats van hen alles te laten raden door de DOM te scrapen.
In een recente post verwijst Bastian Grimm naar de WebMCP-aankondiging en focust hij op één specifiek punt: de aankondiging en de specificatie leggen uit dat HTML-formulieren kunnen worden blootgesteld als tools die door agents gebruikt kunnen worden, op voorwaarde dat ze worden geannoteerd met enkele specifieke attributen. WebMCP probeert het web niet om te vormen tot één grote API, maar net expliciet te maken, voor agents, wat een pagina toelaat: welke acties mogelijk zijn, wat de velden betekenen en hoe een actie wordt getriggerd.
De WebMCP-specificatie beschrijft twee manieren om deze acties bloot te stellen:
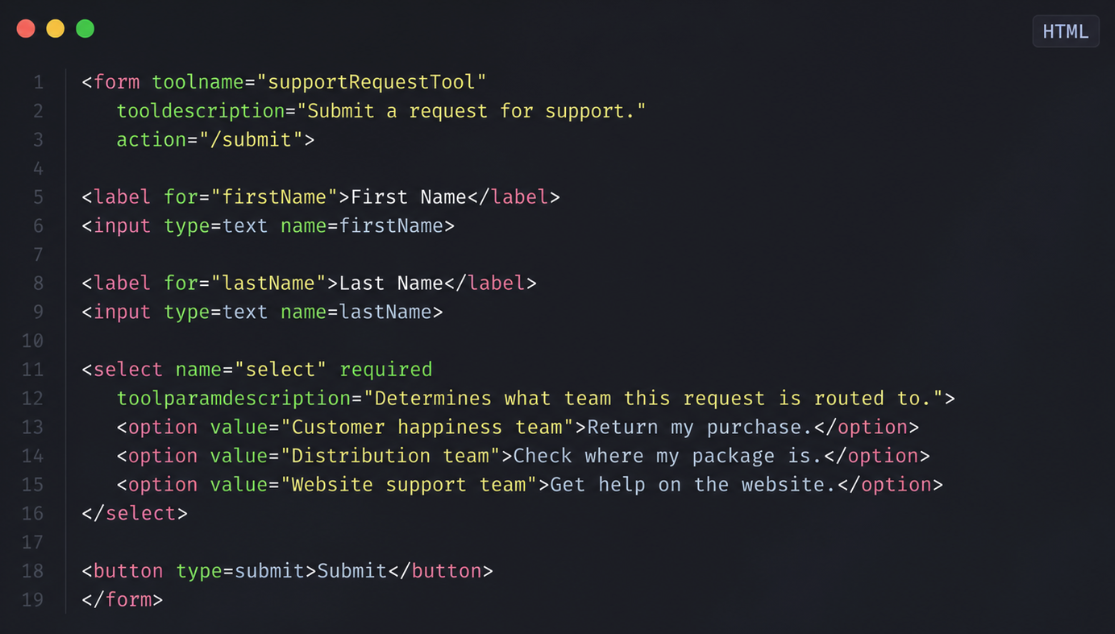
In het declaratieve geval kan een eenvoudige <form> een tool worden die door een agent gebruikt kan worden door enkele attributen toe te voegen zoals toolname (naam van de actie), tooldescription (wat het formulier doet) of toolparamdescription (wat elk veld betekent). De browser zet dit formulier vervolgens om in een gestructureerde representatie die een agent kan gebruiken, op dezelfde manier als een MCP-tool aan serverzijde.
Met andere woorden: hetzelfde zoek-, contact- of reservatieformulier dat gebruikers vandaag invullen kan, met zeer weinig aanpassingen, een duidelijk leesbare en herbruikbare capability worden voor een agent, in plaats van gewoon een UI-blok dat geïnterpreteerd moet worden.
Wat WebMCP duidelijk maakt, is een kloof die al lang bestaat: in HTML geven we aan waar data naartoe moet (action) en hoe (method), maar bijna nooit wat het formulier precies doet of wat elk veld echt betekent.
De nieuwe attributen vullen precies die kloof: ze dwingen om de actie te benoemen en de parameters te documenteren, wat nuttig is voor agents… en heel concreet ook voor toegankelijkheid, onderhoud en leesbaarheid voor mensen.
Vanuit SEO/GEO-perspectief is het niet de bedoeling om meteen WebMCP volledig te implementeren.
De vraag wordt eerder: als een agent een gebruiker zou moeten helpen om een taak uit te voeren op mijn website, wat zou die dan effectief kunnen begrijpen en uitvoeren?
Bij formulieren wordt dat heel concreet:
Als je morgen een correcte toolname en tooldescription zou moeten schrijven voor je belangrijkste formulieren, zou dat vanzelfsprekend zijn, of zou je uiteindelijk de volledige gebruikersflow moeten herontwerpen om het logisch te laten kloppen?
WebMCP lost dat niet allemaal op, maar het biedt wel een nuttige bril: een website niet alleen zien als een verzameling pagina’s, maar als een verzameling goed gedefinieerde acties die op termijn door agents gebruikt kunnen worden.
Een terugkerende reactie rond WebMCP is: “perfect voor scammers en spammers, zij zullen het als eerste gebruiken.”
Dat is geen onredelijke zorg. Elke nieuwe automatiseringsmogelijkheid creëert nieuwe vectoren voor spam, valse leads en massale formulierinzendingen.
De documentatie van Chrome en de discussies rond WebMCP maken ook duidelijk dat de standaard enkel beschrijft hoe tools worden gedeclareerd, maar geen security oplost aan model- of agentzijde. Die verantwoordelijkheid blijft bij websites zelf.
Server-side validatie, rate limiting, anomaliedetectie en bepalen wat wel of niet wordt blootgesteld blijven essentieel.
Zonder in detail te gaan, komen er minstens drie principes naar voren:
WebMCP creëert het spamprobleem niet; het herinnert ons er vooral aan dat een website bruikbaar maken voor agents ook een degelijke backend-hygiëne vereist.
Vandaag bevindt WebMCP zich nog in preview in Chrome, als experimentele functie voor developers.
Het is geen productiestandaard en geen vereiste voor SEO.
Het ecosysteem errond (tools, best practices, security, visibility-strategieën) is nog in volle ontwikkeling.
In een verwante discussie rond llms.txt vatte John Mueller de situatie recent samen met een zin die hier goed op van toepassing is: “prioritize needs before dreams.”
Die discussie ging over een ander bestand en een ander signaal, maar het principe blijft hetzelfde.
WebMCP en het bredere agentic web volgen, ja. Begrijpen waar deze bouwstenen naartoe wijzen, ja. Maar zonder de fundamenten uit het oog te verliezen:
Dat is wat het verschil zal maken voor mensen, en bij uitbreiding voor de agents die hen ondersteunen.
Structuur, expliciete intentie, goed gedefinieerde acties. De fundamenten blijven dezelfde. Wat verandert, is het oppervlak van het web - en de agents die zich erover bewegen.




.svg)



