Er wordt steeds meer gesproken over GEO, AI Search en AEO. Van zichtbaarheid in ChatGPT, aanwezigheid in Perplexity en aanbevelingen in Google AI-modus.
Het vakgebied evolueert snel. Best practices, niet zozeer. In veel teams blijven mensen deze nieuwe omgevingen analyseren met behulp van tools die zijn ontworpen voor het zoeklandschap van vroeger. Deze tools zijn nuttig, maar ze slagen er niet in om een deel vast te leggen van wat er werkelijk gebeurt.
Bij SEO vertrouwen we al lang op impressies, klikken en sessies. Dit model blijft solide. Maar het is niet langer voldoende om uit te leggen hoe inhoud wel of niet circuleert in generatieve omgevingen.
We hebben het minder over ranglijsten. Meer over begrijpen. Over de mogelijkheid om geherformuleerd, geherformuleerd of geïntegreerd te worden in een antwoord.
GA4 is afhankelijk van de browser. Search Console blijft gericht op Google Search. Een deel van de activiteit - met name aan de kant van de AI-crawler - ontsnapt aan deze tools. Serverlogboeken komen natuurlijk terug in de discussie. Niet als iets nieuws. Eerder als iets dat we met een frisse blik herontdekken.
Logboeken vertellen niet het hele verhaal.
Ze maken niet bekend of een pagina wordt geciteerd in een AI-reactie. Ze meten niet rechtstreeks de invloed van een deel van de inhoud. En ze komen niet overeen met het concept van een „sessie” die is opgeslagen in analysetools.
Ze laten echter wel zien wat er aan de kruipende kant gebeurt: wie kruipt, waar, hoe vaak en met wat voor reactie. Het is een vrij rauwe lezing, maar moeilijk te vervangen.
Als je naar je logboeken kijkt, is er vaak een kleine vertraging. De site volgt niet alleen het ritme van zijn gebruikers. Het wordt voortdurend onderzocht door een hele reeks agenten: zoekmachines, sociale bots, externe tools, gespecialiseerde crawlers en AI-agenten met verschillende mate van identificatie.
Deze bezoeken volgen niet dezelfde patronen als menselijke navigatie. In sommige gebieden is er veel mensenhandel. Anderen worden bijna nooit bezocht. Sommige pagina's worden regelmatig opnieuw bekeken. Anderen blijven in de periferie.
Voor SEO/GEO-teams en contentmanagers stelt dit hen in staat om verder te gaan dan een puur theoretisch beeld van de structuur van de site. U kunt zien wat er daadwerkelijk wordt bekeken.
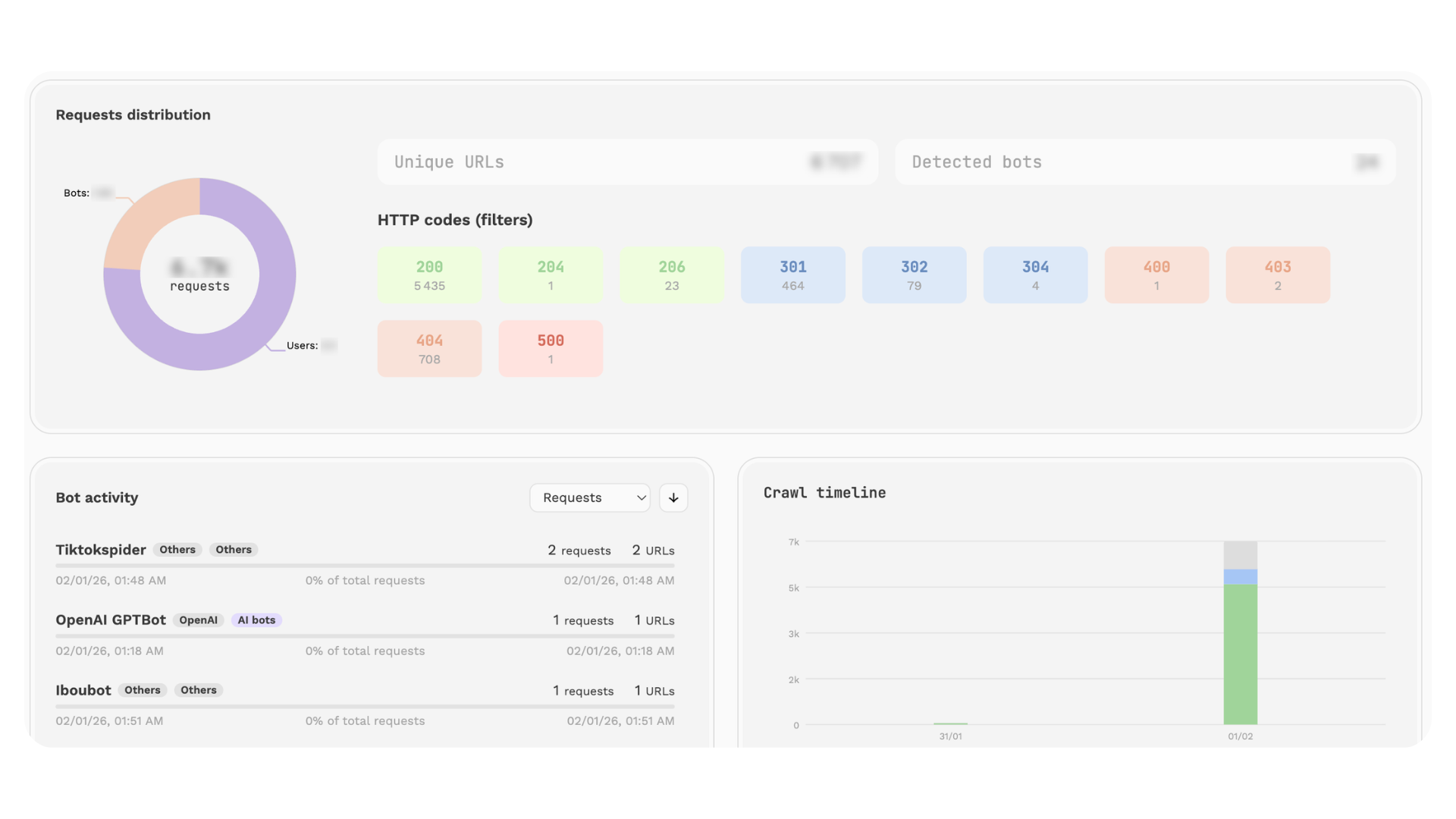
Op een onlangs geanalyseerde e-commercesite blijkt deze discrepantie al uit een logboekuittreksel van één dag. Aan de ene kant is er een overzicht van de crawling; aan de andere kant een uitsplitsing tussen gebruikers en bots, het aantal unieke URL's dat is onderzocht en het aantal gedetecteerde bots. Dit type weergave maakt de zaken snel recht: een aanzienlijk deel van de activiteit op de site ontsnapt volledig aan traditionele tools voor het volgen van doelgroepen.
Gewoon zeggen dat „bots de site crawlen” zegt ons niet veel. Met logboeken kunnen we wat dieper graven.
We kunnen volumes, pieken en distributies waarnemen. Sommige gebieden trekken de meeste aandacht, terwijl andere onder de radar vliegen.
Bepaalde patronen worden duidelijker: basisinhoud die is ontworpen voor SEO of AEO, maar met weinig bezoekers; naast secundaire gebieden die een aanzienlijk deel van de crawls vastleggen. We zien ook gedragingen die in de loop van de tijd sterk geconcentreerd zijn.
Als je wat beter kijkt, worden deze gedragingen duidelijk. Sommige bots genereren honderden verzoeken op verschillende URL's, terwijl andere meer sporadisch handelen. De activiteit kan ook binnen een zeer kort tijdsbestek worden geconcentreerd, wat overeenkomt met intensieve crawlfasen die sterk verschillen van het gebruikersverkeer. Hier gaan we verder dan een algemene analyse naar iets veel preciezers: welke bots bezoeken daadwerkelijk, met welke frequentie en op welke delen van de site.

Het feit dat een bot een pagina bezoekt, is geen garantie dat deze wordt gebruikt in een reactie. En het ontbreken van een zichtbaar bezoek betekent niet dat inhoud afwezig is in het generatieve ecosysteem.
Tussen beide lagen bevinden zich verschillende lagen: indexen, vooraf geïntegreerde gegevens, ophaalsystemen en kruisverwijzingen met andere bronnen.
Hiervoor moet met twee perspectieven worden gewerkt: wat wordt onderzocht en wat wordt er daadwerkelijk gebruikt. Logboeken bieden een goed inzicht in de eerste. Dit laatste vereist andere benaderingen: het observeren van reacties, het analyseren van citaten en het testen van aanwijzingen. De waarde zit in de combinatie.
Eén opmerking komt vrij vaak naar voren: bots brengen veel tijd door waar dingen eenvoudig zijn.
Filters, instellingen, archieven, variaties... bepaalde gebieden nemen een aanzienlijk deel van de crawls voor hun rekening. Ondertussen blijft meer strategische inhoud grotendeels onontgonnen.
Wanneer we de gegevens groeperen op paginacategorieën, ontstaat er een ander soort onbalans. Bepaalde secties nemen een aanzienlijk deel van de treffers voor hun rekening, simpelweg omdat ze gemakkelijk te crawlen zijn. Andere, hoewel meer strategisch, worden nog steeds over het hoofd gezien. Deze analyse stelt ons in staat om snel vast te stellen waar de crawlis geconcentreerd... en waar hij minder tijd doorbrengt dan we zouden denken.
Het probleem is niet langer beperkt tot het produceren van inhoud. Het gaat er ook om ervoor te zorgen dat het toegankelijk is, geïntegreerd is in de structuur en aanwezig is in de paden die bots volgen.
Logboeken onthullen vrij eenvoudige problemen die elders vaak onopgemerkt blijven.
Ketenomleidingen. Terugkerende fouten. Onregelmatige reactietijden. Actieve pagina's met weinig verkeer.
Met logboeken kunt u ook inzoomen tot op het niveau van elk afzonderlijk verzoek. Je kunt precies zien welke URL werd geopend, door welke bot, met welke responscode en in hoeveel tijd. We vinden vaak dat pagina's slechts één keer worden bezocht, met een enkele treffer en zonder dat er gedurende die periode opnieuw wordt gecrawld. Omgekeerd worden sommige URL's doorverwezen of hebben ze langere responstijden, wat het crawlen vertraagt of bemoeilijkt.
Dit detailniveau verandert de aard van de besluitvorming. We repareren „de site” niet langer op een algemene manier. We grijpen in op zeer specifieke pagina's en gedragingen.
Verkeersstatistieken blijven belangrijk. Ze verdwijnen niet.
Maar met AI Search zit een deel van de zichtbaarheid buiten het aantal klikken: in de manier waarop inhoud opnieuw wordt gepost, geherformuleerd en vermeld.
Dit voegt nog een laag toe. We blijven de bedrijfsresultaten volgen. Maar we kijken ook naar de aanwezigheid in de zoekresultaten, de onderwerpen waar het merk verschijnt en hoe inhoud circuleert. Logboeken meten deze zichtbaarheid niet rechtstreeks. Ze laten ons zien of de site deel uitmaakt van de verkenningstrajecten van gebruikers.
Logboeken alleen zijn niet voldoende om een GEO-strategie aan te sturen. Ze laten ons op zichzelf niet begrijpen wat er gebeurt in de generatieve reacties.
Maar ze bieden een concrete basis. Ze laten zien wat er wordt onderzocht en wat niet. De te doelgebieden. De ondergetargete pagina's. De wrijvingspunten.
In een omgeving die nog steeds gedeeltelijk ondoorzichtig is, is het moeilijk om dit soort analyses te negeren.
De aanpak blijft vrij eenvoudig: observeer de crawl zoals die is, identificeer onevenwichtigheden, pas de structuur aan, houd wijzigingen bij en vergelijk vervolgens met wat er gebeurt op het gebied van reacties en zakelijke aspecten.
AI-bots zijn er al. De vraag is of we echt kijken naar wat ze aan het doen zijn.
.avif)



.svg)



