On parle de plus en plus de GEO, d’AI Search, d’AEO. De visibilité dans ChatGPT, de présence dans Perplexity, de recommandation dans Google AI Mode.
Le sujet avance vite. Les pratiques, un peu moins. Dans beaucoup d’équipes, on continue à analyser ces nouveaux environnements avec des outils pensés pour le search d’avant. Des outils utiles, mais qui ne captent pas une partie de ce qui est en train de se passer.
En SEO, on a longtemps piloté avec des impressions, des clics, des sessions. Ce modèle reste solide. Mais il ne suffit plus à expliquer comment un contenu circule - ou ne circule pas - dans les environnements génératifs.
On parle moins de position. Plus de compréhension. De capacité à être repris, reformulé, intégré dans une réponse.
GA4 dépend du navigateur. Search Console reste centré sur Google Search. Une partie de l’activité - notamment côté crawlers IA - échappe à ces outils. Les logs serveur reviennent alors naturellement dans la discussion. Pas comme une nouveauté. Plutôt comme quelque chose qu’on redécouvre avec un autre regard.
Les logs ne racontent pas toute l’histoire.
Ils ne permettent pas de savoir si une page sera citée dans une réponse IA. Ils ne mesurent pas directement l’influence d’un contenu. Et ils ne correspondent pas à une notion de “session” telle qu’on la suit dans les outils analytics.
En revanche, ils montrent ce qui se passe côté crawl. Qui passe. Où. À quelle fréquence. Avec quel type de réponse. C’est une lecture assez brute, mais difficile à remplacer.
Quand on ouvre ses logs, il y a souvent un petit décalage. Le site ne vit pas seulement au rythme des utilisateurs. Il est exploré en continu par toute une série d’agents : moteurs, bots sociaux, outils externes, crawlers spécialisés, agents IA plus ou moins identifiés.
Ces passages ne suivent pas les mêmes logiques que les parcours humains. Certaines zones sont très sollicitées. D’autres presque jamais. Certaines pages reviennent régulièrement. D’autres restent en périphérie.
Pour les équipes SEO / GEO, pour les content managers, cela permet de sortir d’une vision uniquement théorique de la structure. On voit ce qui est réellement parcouru.
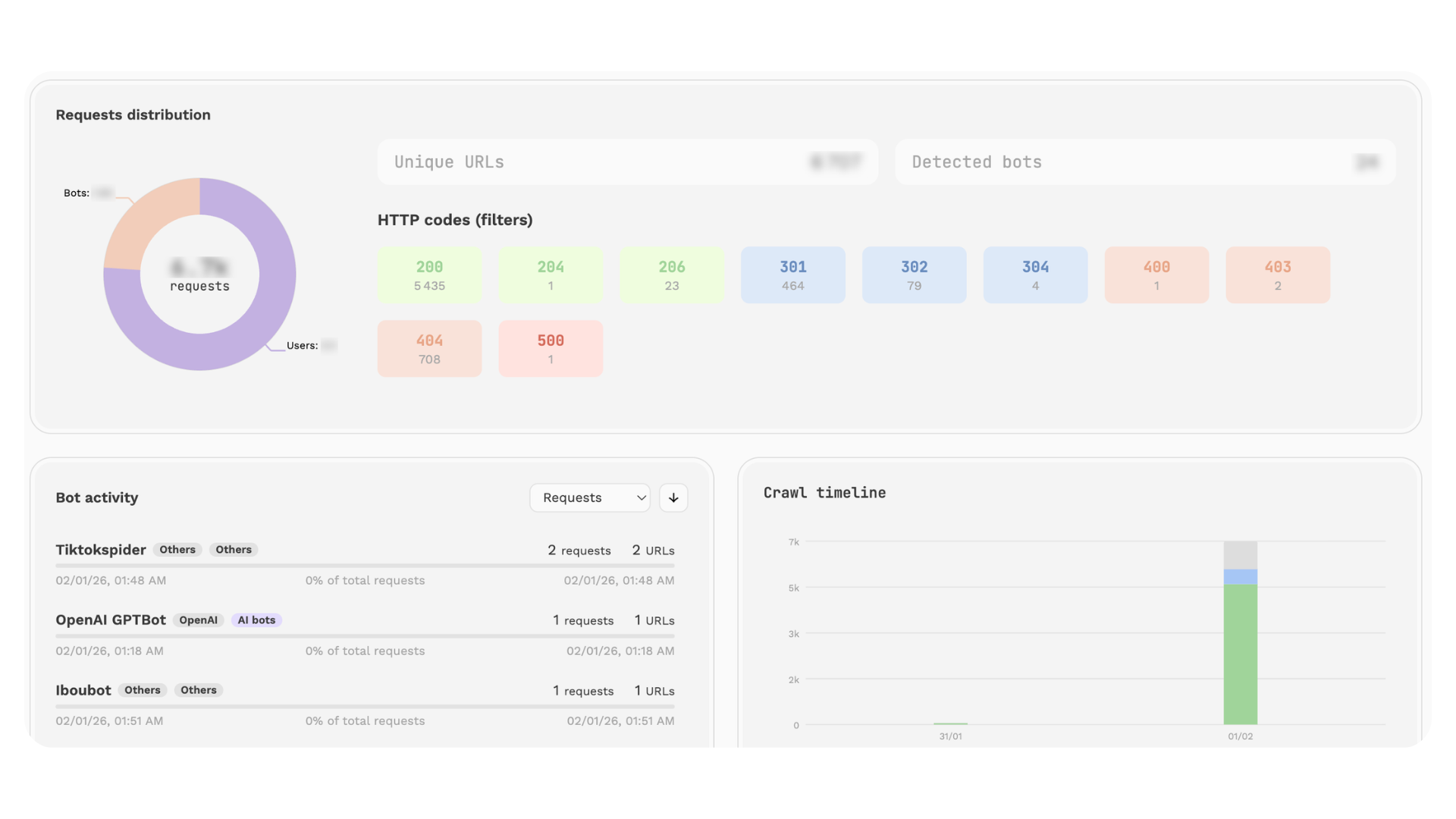
Sur un site e-commerce analysé récemment, un extrait de logs sur une seule journée montre déjà cet écart. On y retrouve d’un côté une vue globale du crawl, de l’autre une répartition entre utilisateurs et bots, le volume d’URLs uniques explorées et le nombre de bots détectés. Ce type de vue remet rapidement les choses à plat : une part significative de l’activité du site échappe complètement aux outils d’audience classiques.
Dire que “les bots crawlent le site” n’apprend pas grand-chose. Les logs permettent d’aller un peu plus loin.
On observe des volumes, des pics, des répartitions. Des zones qui concentrent l’attention. D’autres qui passent sous le radar.
Certaines situations deviennent plus lisibles : des contenus structurants, pensés pour le SEO ou l’AEO, mais peu visités ; à côté, des zones secondaires qui captent une part importante du crawl. Des comportements aussi très concentrés dans le temps.
En regardant un peu plus en détail, les comportements deviennent lisibles. Certains bots génèrent plusieurs centaines de requêtes sur des URLs distinctes, d’autres interviennent de manière plus ponctuelle. L’activité peut aussi se concentrer sur une fenêtre de temps très courte, ce qui correspond à des phases de crawl intensives, très différentes d’un trafic utilisateur. Là, on sort d’un raisonnement global pour entrer dans quelque chose de beaucoup plus précis : quels bots passent réellement, à quel rythme, et sur quelles zones du site.

Le passage d’un bot sur une page ne garantit rien sur son utilisation dans une réponse. Et l’absence de passage visible ne signifie pas qu’un contenu est absent de l’écosystème génératif.
Entre les deux, il y a plusieurs couches : index, données déjà intégrées, systèmes de récupération, croisement avec d’autres sources.
Cela oblige à travailler avec deux lectures : ce qui est exploré, et ce qui est réellement mobilisé. Les logs donnent une bonne visibilité sur la première. La seconde demande d’autres approches : observation des réponses, analyse de citations, tests de prompts. L’intérêt vient de la combinaison.
Un constat revient assez souvent : les bots passent beaucoup de temps là où c’est simple.
Filtres, paramètres, archives, variantes… certaines zones captent une part importante du crawl. Pendant ce temps, des contenus plus stratégiques restent peu explorés.
Quand on regroupe les données par catégories de pages, un autre type de déséquilibre apparaît. Certaines sections concentrent une part importante des hits, simplement parce qu’elles sont faciles à explorer. D’autres, pourtant plus stratégiques, restent en retrait. Cette lecture permet d’identifier rapidement où le crawl se concentre… et où il passe moins qu’on ne le pense.
Le sujet ne se limite plus à produire du contenu. Il s’agit aussi de s’assurer qu’il est accessible, intégré dans la structure, présent dans les parcours que les bots suivent.
Les logs font remonter des choses assez basiques, mais qui passent souvent inaperçues ailleurs.
Des redirections en chaîne. Des erreurs récurrentes. Des temps de réponse irréguliers. Des pages actives mais peu sollicitées.
Les logs permettent aussi de descendre au niveau de chaque requête. On peut voir précisément quelle URL a été appelée, par quel bot, avec quel code de réponse et en combien de temps. On retrouve souvent des pages visitées une seule fois, avec un seul hit et aucun recrawl sur la période. À l’inverse, certaines URLs passent par des redirections ou présentent des temps de réponse plus élevés, ce qui ralentit ou complique l’exploration.
Ce niveau de détail change la nature des arbitrages. On ne corrige plus “le site” de manière globale. On intervient sur des pages et des comportements très précis.
Les métriques de trafic restent importantes. Elles ne disparaissent pas.
Mais avec l’AI Search, une partie de la visibilité se construit en dehors du clic. Dans la manière dont les contenus sont repris, reformulés, mentionnés.
Cela ajoute une couche. On continue à suivre les résultats business. Mais on regarde aussi la présence dans les réponses, les sujets sur lesquels la marque apparaît, la manière dont les contenus circulent. Les logs ne mesurent pas directement cette visibilité. Ils permettent de voir si le site entre dans les parcours d’exploration.
Les logs ne suffisent pas à piloter une stratégie GEO. Ils ne permettent pas, seuls, de comprendre ce qui se passe dans les réponses génératives.
Mais ils apportent une base concrète. Ils montrent ce qui est exploré. Ce qui ne l’est pas. Les zones sursollicitées. Les pages en retrait. Les points de friction.
Dans un environnement encore partiellement opaque, ce type de lecture devient difficile à ignorer.
La démarche reste assez simple : observer le crawl tel qu’il est, repérer les déséquilibres, ajuster la structure, suivre les évolutions, puis croiser avec ce qui se passe côté réponses et business.
Les bots IA sont déjà là. Reste à savoir si on regarde vraiment ce qu’ils font.
.avif)



.svg)



