Samengevat - In het GEO-tijdperk volstaat het niet langer om online te bestaan - je moet bestaan als een erkende, onderscheidende en gecorroboreerde entiteit. Twee Céline Naveaus in hetzelfde Belgische professionele ecosysteem, twee Danny Goodwins die Google tien jaar lang verwarde, één Michael King die het probleem oploste voordat het concept bestond - al deze situaties illustreren hetzelfde probleem. AI-zoekmachines (ChatGPT, Perplexity, Google AI Overviews) verzoenen vage identiteiten niet: ze negeren ze. Je named entity opbouwen en verdedigen is niet langer optioneel. Het is de voorwaarde voor je zichtbaarheid in door AI gegenereerde antwoorden.
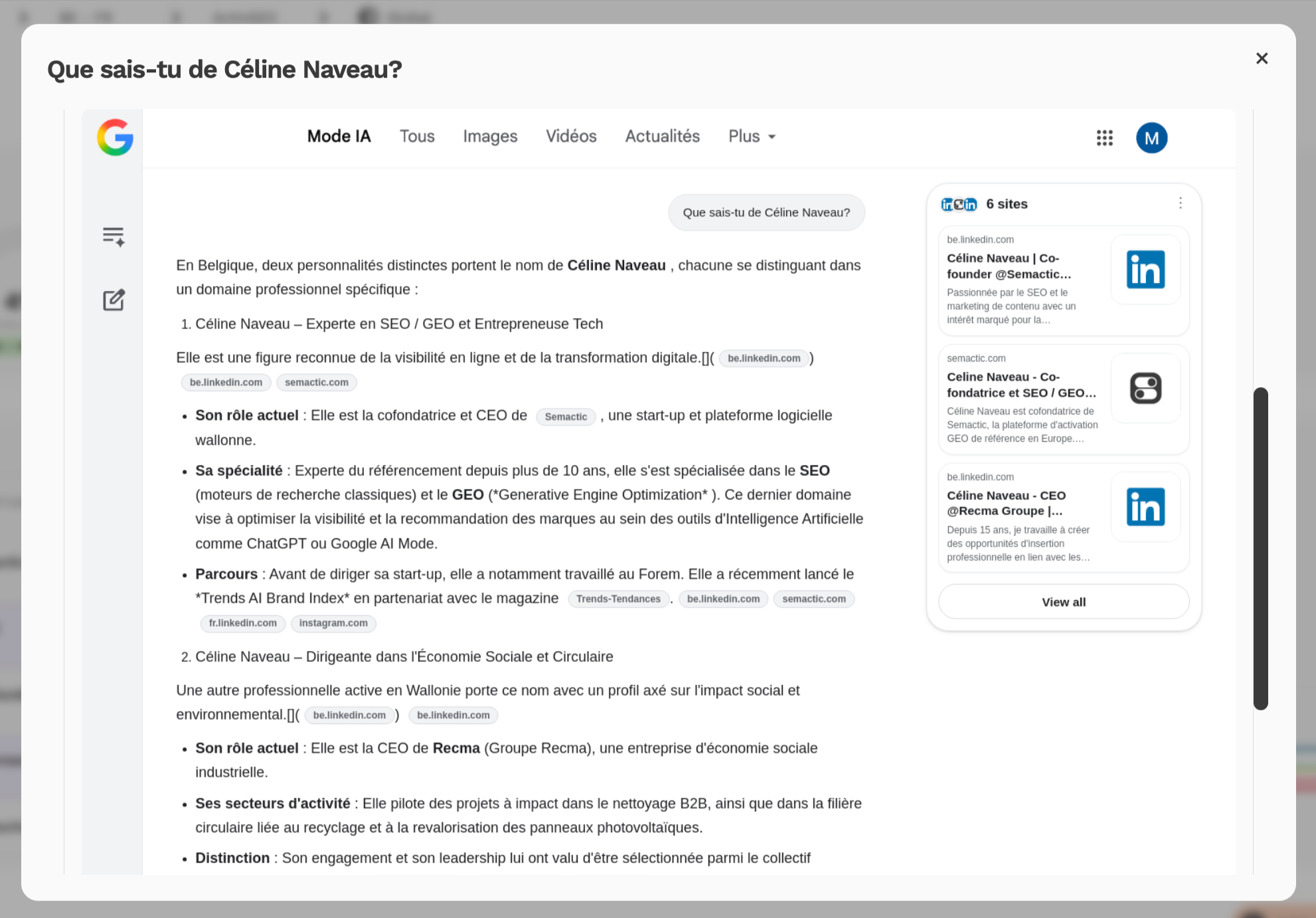
Perplexity ondervraagd over "Céline Naveau": de AI-zoekmachine identificeert haar duidelijk als de meest zichtbare persoon onder die naam in België, medeoprichter van Semactic en GEO-specialist. Bron: Perplexity
Tot mijn 24ste dacht ik dat ik vrij uniek was. Mijn naam - Naveau - voelde zeldzaam, bijna een handtekening, een erfenis uit mijn geboortestreek Chimay. Toen gebeurde het. In twee bedrijven.
Bedrijf 1. Op het Forem, op dezelfde dag aangeworven als een collega met dezelfde familienaam. Gelukkig een andere voornaam. Een klassieke kantooranekdote, verder niets.
Bedrijf 2. Een echte naamgenote. Een andere Céline Naveau - een mooi parcours, aanwezig in dezelfde Belgische professionele kringen, en Belgium's 40 under 40 gemeen. Ik heb nooit echt geweten of ik per vergissing geselecteerd was. Voor de twijfel besloot ik het als een compliment te beschouwen. Goed gedaan, Céline. 😄
Het had daarbij kunnen blijven. Maar ik werk al sinds 2020 op de AI-evolutie van zoekmachines. En in de GEO-wereld is een vage identiteit geen grappig verhaal meer. Het is een structureel risico.
ChatGPT ondervraagd over "Céline Naveau": het model mengt beide profielen en combineert attributen die toebehoren aan twee afzonderlijke personen. Bron: persoonlijke screenshot
Het verhaal van Danny Goodwin: wanneer Google tien jaar lang twee mensen verwisselt
Ik sta hierin niet alleen. En sommige situaties zijn aanzienlijk ernstiger. Danny Goodwin, eindredacteur van Search Engine Land, deelt zijn naam met een honkballer in de Hall of Fame. Het gevolg? Meer dan een decennium lang behandelde de Knowledge Graph van Google beide mannen als één en dezelfde persoon.
De situatie was kritiek: geen eigen aanwezigheid in de Knowledge Graph, geen Knowledge Panel, en artikelen toegeschreven aan de honkballer.
"Google was er absoluut van overtuigd dat Danny Goodwin de honkballer dezelfde persoon was als Danny Goodwin van Search Engine Land. Voor een mens is dat uiteraard absurd. Maar het algoritme steunt op de 'weight of probability' die het afleidt uit beschikbare publieke informatie." - Jason Barnard, Kalicube
Zoals bleek uit het Google-lek van 2024, voedt de Knowledge Graph zichzelf met eigen synthetische data en versterkt het zijn bestaande aannames bij elke update. Een entiteitsverwarring doorsnijdt het isAuthor-signaal en leidt alle merkwaarde om naar de verkeerde entiteit.
Wat een named entity is - en waarom het de basis van alles vormt
In natural language processing en semantische SEO verwijst een named entity naar een object uit de echte wereld - een persoon, organisatie, locatie of concept - dat informatiesystemen ondubbelzinnig kunnen identificeren, indexeren en verbinden met andere entiteiten. Google bouwt een representatie van de wereld via zijn Knowledge Graph, waar elke entiteit een unieke identifier krijgt: de KGMID. Denk eraan als je rijksregisternummer op het internet. Zonder dat nummer besta je niet als erkende entiteit.
Voor een correcte herkenning en disambiguering zijn drie voorwaarden vereist: distinctie (je attributen onderscheiden je duidelijk), consistentie (diezelfde attributen zijn identiek op al je platformen) en corroboratie (onafhankelijke bronnen bevestigen die attributen).
Het verhaal van Michael King: een entity-architectuurbeslissing voordat het concept bestond
Michael King, oprichter van iPullRank, draagt een van de meest voorkomende namen ter wereld. Hij had zijn volledige digitale aanwezigheid kunnen bouwen rondom "Michael King". Hij koos het tegenovergestelde: vanaf het begin creëerde hij iPullRank als persoonlijk merk - een unieke naam, onmogelijk te verwarren met wie dan ook. Zoek naar "Michael King": je vindt acteurs, politici, atleten. Zoek naar "iPullRank": je vindt hem, en alleen hem.
De les is niet "creër een pseudoniem". De les is: begrijp hoe informatiesystemen jou representeren, en neem de controle over die representatie.
In het GEO-tijdperk worden named entities existentieel
In klassieke SEO kost een entiteitsverwarring je posities. In GEO kan het je volledige aanwezigheid kosten in de antwoorden van AI-zoekmachines. LLM's - ChatGPT, Perplexity, Google AI Overviews - geven geen lijst van links terug. Ze synthetiseren een antwoord op basis van vertrouwenssignalen. Wat helder, consistent en gecorroboreerd is, komt in de antwoorden terecht. De rest is ruis.
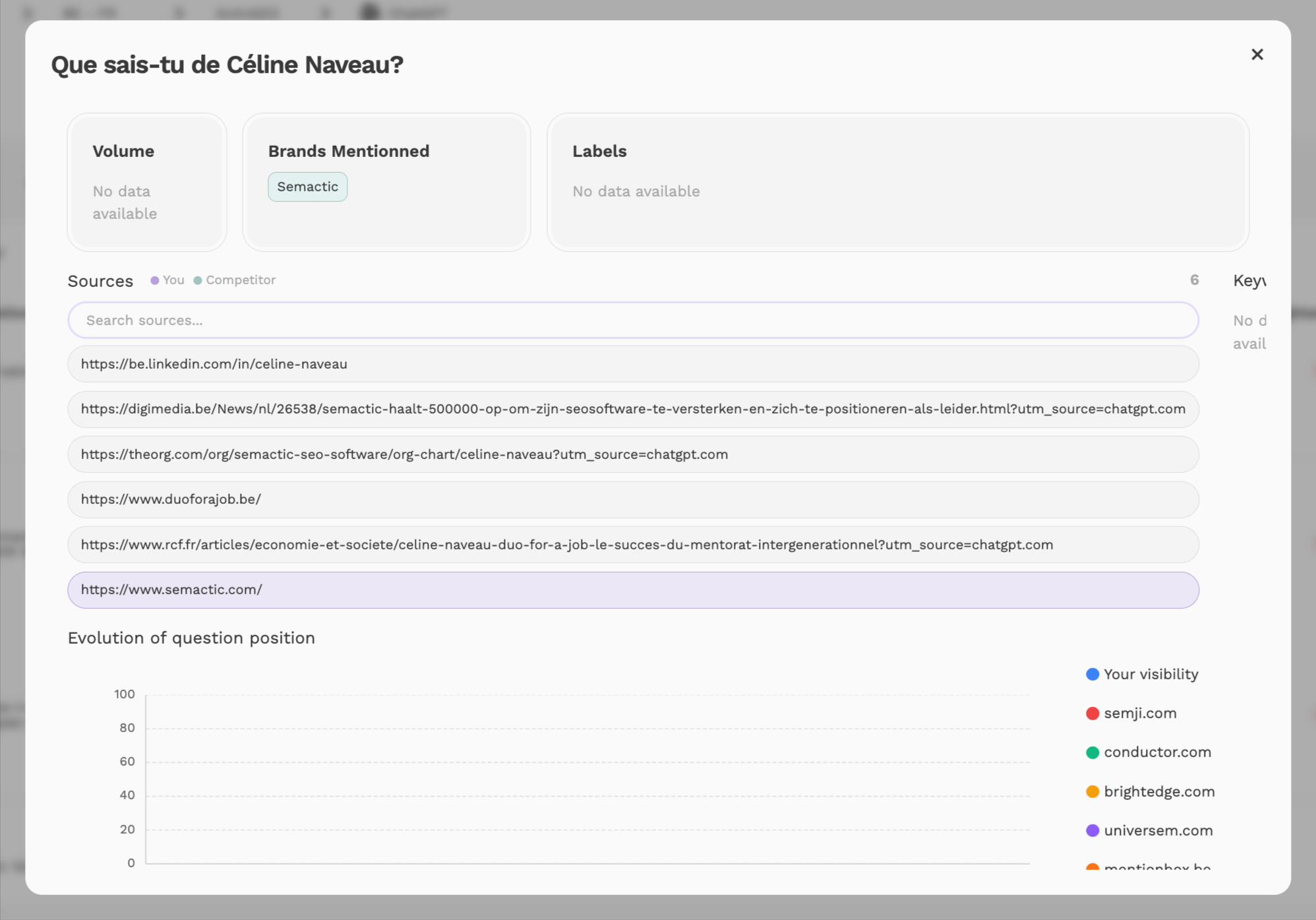
De Semactic-app biedt een concrete meting van de zichtbaarheid van een named entity in AI-zoekmachines - en identificeert de ontbrekende signalen. Bron: app Semactic
Hoe entiteitsverwarring oplossen: de 3 bewezen stappen
De ervaring van Danny Goodwin biedt ons een concreet stappenplan. Jason Barnard (Kalicube) loste één van de meest complexe situaties op die hij in 13 jaar entiteitsoptimalisatie tegenkwam.
Stap 1 - Bouw een Entity Home. Een canonieke referentiepagina die centraliseert wie je bent, je expertisedomein, je geografie en je professionele associaties, met expliciete schema.org Person- of Organization-markup. In Goodwins situatie was zelfs een eenvoudige WordPress-website met twee pagina's voldoende.
De Entity Home van Danny Goodwin: een minimalistische site, twee pagina's, geen verfijnd design - maar onberispelijke semantische markup en consistente attributen. Bron: Jason Barnard / Kalicube (Search Engine Land)
Stap 2 - Schrijf een ondubbelzinnige samenvatting. Een biografie die opent met een eenvoudig semantisch drieluik: "[Voornaam Naam] is [Functietitel] bij [Organisatie]." Één duidelijk, verankerd feit waarop het algoritme kan steunen.
Stap 3 - Creër een corroboratielus. Update je digitale voetafdruk consistent: sociale profielen, auteurspagina's, bronnen van derden (Crunchbase, The Org, persartikelen). Elke pagina moet dezelfde attributen weerspiegelen en teruglinken naar de Entity Home.
In Goodwins situatie, ondanks de extreme complexiteit: 4 maanden voor een unieke identifier, 6 maanden voor Knowledge Panel cards, 9 maanden voor een stabiele beschrijving, 12 maanden voor de juiste People also search for. En toen Google AI Mode werd gelanceerd, presenteerde het de twee Danny Goodwins meteen als afzonderlijke entiteiten.
Concrete hefbomen om je named entity op te bouwen en te verdedigen
De Entity Home - met expliciete schema.org Person- of Organization-markup.
Consistentie van attributen - naam, titel, domein en locatie identiek op al je platformen.
Onafhankelijke vermeldingen door derden - artikelen, interviews, citaten in gezaghebbende bronnen.
sameAs-markup - links naar je LinkedIn-profiel en andere online referenties.
Voorbeeld van JSON-LD schema.org/Person-markup met sameAs-eigenschappen - de digitale handtekening van je entiteit. Bron: app Semactic
Semactic analyseert de volledige set entiteitssignalen en identificeert de hiaten die moeten worden aangepakt. Bron: app Semactic
Mijn volgende project: op mezelf toepassen wat ik bij anderen observeer
Ik medeorganiseer de GEO Summit. Ik werk al sinds 2024 aan LLM-zichtbaarheid. Ik documenteer de implicaties van taalmodellen op search al sinds 2020. En mijn eigen named entity? Die is in volle opbouw. 😅
Twee Céline Naveaus in hetzelfde Belgische professionele ecosysteem, met overlappende signalen - dat is precies het scenario dat ik aan elke klant zou beschrijven als een prioritair risico. Het is tijd om zelf consequent te zijn. Op het programma: een gestructureerde Entity Home, volledige consistentie van mijn attributen op alle digitale platformen, en voldoende dichte contextsignalen zodat Google - en ChatGPT - precies weten over welke Céline Naveau het gaat.
De andere Céline Naveau hoeft zich geen zorgen te maken. 😄
In SEO én in GEO wint niet het beste parcours. Het wint de best gedocumenteerde entiteit. Aan de slag dus.
Céline Naveau
Céline Naveau is medeoprichter van Semactic, het toonaangevende GEO-activatieplatform van Europa. Met meer dan 10 jaar expertise in search focust ze zich op de evolutie van zichtbaarheidsstrategieën in het tijdperk van AI Search, waarin merken niet langer alleen zichtbaar moeten zijn, maar ook aanbevolen, geciteerd en gekozen moeten worden. Met Semactic helpt ze mee vorm te geven aan een meer actiegerichte, meetbare en ambitieuze aanpak van organische aanwezigheid, ontworpen om bedrijven te helpen evolueren van observatie naar activatie, en van zichtbaarheid naar impact.
Als je marketing vastzit in de planningsmodus, ben je niet de enige. De meeste inkomende strategieën lopen niet vast vanwege een slecht idee, maar omdat ze nooit worden geïmplementeerd.
.svg)





.avif)






